
서비스 추상화
자바에는 표준 스펙, 상용 제품, 오픈 소스를 통틀어서 사용 방법과 형식은 다르지만 기능과 목적이 유사한 기술이 존재한다. 환경과 상황에 따라 기술이 바뀌고, 그에 따른 API를 사용하고 다른 스타일의 접근 방법을 따라야 한다는 것은 매우 피곤한 일이다.
지금까지 만든 DAO에 트랜잭션을 적용해보며 스프링이 어떻게 성격이 비슷한 여러 종류의 기술을 추상화하고 이를 일관된 방법으로 사용할 수 있도록 지원하는지 알아보자.
사용자 레벨 관리 기능 추가
현재 UserDao에서는 소위 CRUD라고 말하는 기능만 제공한다. 그 외에 어떠한 비즈니스 로직도 제공하지 않는다. 새로운 요구사항이 들어와서 단지 정보를 넣고 검색하는 것 외에도 정기적으로 사용자의 활동내역을 참고해서 레벨을 조정해주는 기능이 필요하다고 가정해보자.
요구사항
- 사용자의
Level은Basic,Silver,Gold중 하나다. - 사용자가 처음 가입하면
Basic레벨이 되며, 이후 활동에 따라 조건부로 한 단계씩 업그레이드 된다.- 가입 후 50회 이상 로그인하면
Silver회원이 된다. Silver레벨인 상태에서 추천을 30번 이상 받으면Gold회원이 된다.
- 가입 후 50회 이상 로그인하면
- 사용자 레벨의 변경 작업은 주기를 가지고 일괄적으로 진행된다. 변경 작업 전에는 조건을 충족해도 레벨의 변경이 일어나지 않는다.
간단한 배치작업을 이용해 수행할 수 있다.
필드 추가
Level Enum 추가
첫 요구사항을 충족하기 위해 Level을 만들어야 한다고 가정하자. Level을 저장할 때, DB에는 varchar 타입으로 선언하고, "BASIC", "SILVER", "GOLD"로 저장할 수도 있겠지만, 약간의 메모리라도 중요한 케이스라고 가정하고, 각 레벨을 코드화해서 숫자로 넣는다고 가정하자.
숫자로 넣기로 했다고 가정하면, User 객체에 추가할 프로퍼티도 Integer 타입의 level 프로퍼티를 만드는 것이 좋을까? 상수적이며 범위가 한정적인 데이터를 코드화해서 사용할 때는 ENUM을 이용해 구성하는 편이 좋다. 왜냐하면 단순히 1, 2, 3과 같은 코드 값을 넣으면 작성자 외에는 1이 어떤 Level을 가리키는 것인지 알 방법이 없다.
의미가 명확하지 않은 숫자를 프로퍼티에 사용하면 타입이 안전하지 않아서 위험할 수 있다. 헷갈리기 너무 쉽다.
사실
Level을 넣을 때, 코드화한 숫자보다는 문자열 그대로 넣는 것이 좋다고 생각한다. 숫자로 넣는 경우 본의 아니게 대소관계가 생길 수 있는데1=BASIC2=SILVER3=GOLD로 점점 높은 등급이 되는 명확한 대소관계가 있는 상태에서1.5=BRONZE가 낄 수는 없다. 만일2=BRONZE로 하고 싶다면, 이미 데이터가 많이 쌓인 상태에서 기존에 쌓였던 데이터에 대해 전부 수정을 거쳐야 한다. 기존 데이터를 건들지 않고 살짝 추가만 하고 싶다면,4=BRONZE와 같이 뭔가 탐탁치 않은 방식으로 해결해야 한다.
public class User {
private static final int BASIC = 1;
private static final int SILVER = 2;
private static final int GOLD = 3;
int level;
public setLevel(int level) {
this.level = level;
}
...if (user1.getLevel() == User.BASIC) {
user1.setLevel(User.SILVER);
}위는 ENUM을 사용하지 않은 코드이다. 위와 같이 단순히 static int형 상수로 정의하면 BASIC, SILVER, GOLD와 같이 코드를 작성하여 의미있는 코드 작성은 가능하지만, 누군가 그냥 0, 4, 5 등 우리가 정의한 Level의 코드 범위에 속하지 않는 값을 넣으면 속수무책으로 당하고 만다. 컴파일러 단계에서 체크해줄 수 없다.
물론 Setter에서 if문을 걸어서 BASIC, SILVER, GOLD가 아닌 경우 Exception을 날리도록 할 수도 있겠지만, 런타임에서 체크를 하는 것이어서 프로그램을 실행한 이후에나 잘못 입력했는지 알 수 있을 것이다.
정확하게 하려면 Level의 도메인 자체를 ENUM 클래스로 분리해서 관리하는 편이 훨씬 깔끔하다. ENUM 클래스로 분리하면 자연적으로 허가되지 않은 단순한 int 값은 못들어오며, 추후에 Level에 대한 요구사항이 확장되었을 때도 해당 도메인에 대한 코드 확장이 용이해진다.
public enum Level {
BASIC(1), SILVER(2), GOLD(3);
private final int value;
Level(int value) {
this.value = value;
}
public int intValue() {
return value;
}
public static Level valueOf(int value) {
return switch (value) {
case 1 -> BASIC;
case 2 -> SILVER;
case 3 -> GOLD;
default -> throw new AssertionError("Unknown value: " + value);
};
}
}Level 도메인에 대한 책임을 맡을 훌륭한 ENUM 클래스가 생성되었다. 이제 컴파일 타임에 잘못된 int 값이 setLevel()로 들어올 위험성은 줄였다.
User 필드 추가
public class User {
...
Level level;
int loginCount;
int recommendCount;
public Level getLevel() {
return level;
}
...ENUM 클래스로 생성한 Level과 함께 로그인 회수를 카운트할 loginCount과 추천 회수를 카운트할 recommendCount도 추가했다.
DB의
User테이블에도 위 값이 담길 필드를 추가해주자.

Postgres 기준으로 위와 같은 타입과 이름으로 만들었다.
public User(String id, String name, String password, Level level, int loginCount, int recommendCount) {
this.id = id;
this.name = name;
this.password = password;
this.level = level;
this.loginCount = loginCount;
this.recommendCount = recommendCount;
}생성자도 위와 같이 새로 만들어주었다.
UserDaoTest 수정
public class UserDaoTest {
...
@BeforeEach
public void setUp() {
userDao.deleteAll();
this.user1 = new User("user1", "김똘일", "1234", Level.BASIC, 1 ,0);
this.user2 = new User("user2", "김똘이", "1234", Level.SILVER, 55, 10);
this.user3 = new User("user3", "김똘삼", "1234", Level.GOLD, 55, 10);
this.user4 = new User("user4", "김똘사", "1234", Level.BASIC, 1, 0);
}기존의 픽스쳐들에도 Level과 loginCount, recommendCount를 추가하여 넣어주었다.
private void checkSameUser(User user1, User user2) {
assertEquals(user1.getId(), user2.getId());
assertEquals(user1.getName(), user2.getName());
assertEquals(user1.getPassword(), user2.getPassword());
assertEquals(user1.getLevel(), user2.getLevel());
assertEquals(user1.getLoginCount(), user2.getLoginCount());
assertEquals(user1.getRecommendCount(), user2.getRecommendCount());
}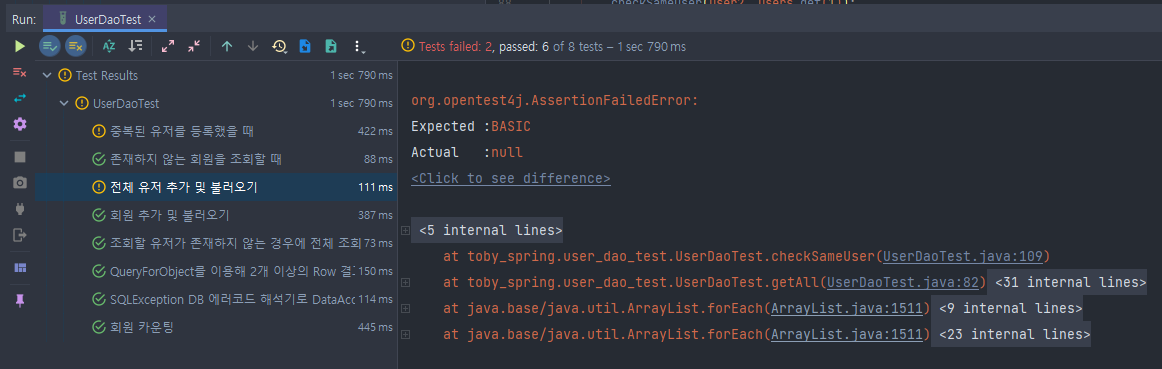
바꿨으니 테스트가 잘 작동하는지 확인해보면, 2가지 테스트가 실패하는 것을 볼 수 있다. DB에 새로 생겨난 컬럼이 클래스에 잘 매핑되지 않고 있는 것 같다.
UserDaoJdbc 수정
public UserDaoJdbc() {
this.userRowMapper = (rs, rowNum) -> {
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
user.setLevel(Level.valueOf(rs.getInt("level")));
user.setLoginCount(rs.getInt("login_count"));
user.setRecommendCount(rs.getInt("recommend_count"));
return user;
};
}먼저 매핑을 위와 같이 수정해준다. 이제 DB에서 데이터를 불러왔을 때 User 객체에는 잘 반영될 것이다.
public void add(User user) throws DuplicateUserIdException {
try {
this.jdbcTemplate.update("insert into users(id, name, password, level, login_count, recommend_count) values (?, ?, ?, ?, ?, ?)"
, user.getId()
, user.getName()
, user.getPassword()
, user.getLevel().intValue()
, user.getLoginCount()
, user.getRecommendCount()
);
} catch (DuplicateKeyException e) {
throw new DuplicateUserIdException(e);
}
}반대 입장에서도 자바의 User 객체가 DB에 잘 매핑되도록 add() 메소드를 잘 수정해주었다. Level 필드의 경우, Level 객체 그대로 매핑은 불가능하니 .intValue()라는 메소드를 이용해서 int 값으로 매핑해주었다.
반대로 DB에서 User 객체를 조회할 때는 int 값을 가져와서 Level.valueOf()를 이용해서 Level 객체로 다시 전환해준다.
만일 이 부분에서 문자열로 작성된 SQL에 실수가 있었다면 어땠을까? 실행 전까지는 IDE내에서 어떠한 에러도 발견하지 못하고, 런타임 상태가 돼서야
BadSqlGrammerException이라는 예외를 날렸을 것이다.JDBC가 사용하는 SQL은 컴파일 과정에서는 자동으로 검증이 되지 않는 단순 문자열에 불과하다. 그러나, 우리는 꼼꼼하게
UserDao에서 생성한 모든 메소드에 대한 테스트를 작성해두었기 때문에 실제 서비스로 올라가기 전에 테스트만 돌려봤어도 해당 에러를 잡을 수 있었을 것이다.테스트를 작성하지 않았다면, 실 서비스 실행 중에 예외가 날아다녔을 것이고, 한참 후에 수동 테스트를 통해 메세지를 보고 디버깅을 해야 그제서야 겨우 오타를 확인할 수 있었을 것이다.
그때까지 진행한 빌드와 서버 배치, 서버 재시작, 수동 테스트 등에 소모한 시간은 낭비에 가깝다.
빠르게 실행 가능한 포괄적인 테스트를 만들어두면 이렇게 기능의 추가나 수정이 일어날 때 그 위력을 발휘한다.
사용자 수정 기능 추가
사용자 관리 비즈니스 로직에 따르면 사용자 정보는 여러번 수정될 수 있다. 때때론 성능 최적화를 위해 수정되는 필드의 종류에 따라 여러 개의 수정용 DAO 메소드를 만들어야 할 때도 있지만, 아직 사용자 정보가 단순하고 필드도 몇개 되지 않고 수정이 자주 일어나지 않으므로 간단히 접근해보자.
수정 기능 테스트 추가
@Test
@DisplayName("사용자 수정 기능 테스트")
public void update() {
userDao.add(user1);
user1.setName("오민규");
user1.setPassword("2345");
user1.setLevel(Level.GOLD);
user1.setLoginCount(1000);
user1.setRecommendCount(999);
userDao.update(user1);
User user1update = userDao.get(user1.getId());
checkSameUser(user1, user1update);
}실패하는 테스트를 먼저 작성하자. 기본키인 id를 제외한 나머지 내용을 바꾸고 DB에서 다시 해당 사용자를 조회하여 DB에 있는 내용과 객체에 있는 내용이 일치하여 DB에 잘 반영됐는지 확인한다.
UserDao와 UserDaoJdbc 수정
public interface UserDao {
void add(User user);
User get(String id);
User getByName(String name);
List<User> getAll();
void deleteAll();
int getCount();
void update(User user1);
}UserDao에도 update() 메소드를 추가해주자.
@Override
public void update(User user) {
this.jdbcTemplate.update(
"update users set name = ?, password = ?, level = ?, login_count = ?, recommend_count = ? where id = ? "
, user.getName(), user.getPassword(), user.getLevel().intValue(), user.getLoginCount(), user.getRecommendCount(), user.getId()
);
}SQL 기본 문법만 알고 있으면 매우 쉽다.
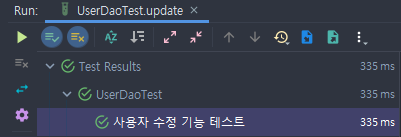
테스트도 잘 작동하는 것을 확인했으니, 다음으로 넘어가자.
수정 테스트 보완
기본 수정 테스트는 성공했지만, 꼼꼼한 개발자라면 이 테스트에 뭔가 불만을 가지고 의심스럽게 코드를 다시 살펴봐야 한다. JDBC 개발에서 가장 많은 실수가 일어날만한 곳은 아무래도 컴파일러가 잡아주지 못하는 SQL 문자열 부분이다.
차라리 SQL의 문법을 틀렸다면, 런타임 도중에 예외가 날테지만 update에서 where절과 같은 부분을 빼먹으면 난감하다. 테스트는 정상적으로 동작하는데 결과는 이상한 경우가 발생할 수 있다.
이러한 문제를 해결하려면 두가지 방법이 있다.
첫번째 방법은 JdbcTemplate의 update()가 돌려주는 반환 값을 확인하는 것이다. JdbcTemplate의 update()는 UPDATE, DELETE와 같이 테이블의 내용에 영향향을 주는 SQL을 실행하면 영향받은 로우의 개수를 돌려준다.
where를 사용하지 않았다면, 모든 row가 변경될 것이기 때문에, 1보다 큰 숫자가 나올 수 있다. 혹은 잘못된 조건을 사용했다면 아무런 row도 변경되지 않았기 때문에 0이 나올 것이다. 1인지 확인하는 코드를 하나 더 추가해주면 된다.
두번째 방법은 테스트를 보강해서 원하는 사용자 외의 정보는 변경되지 않았음을 직접 확인하는 것이다. 사용자를 두 명 등록해놓고, 그 중 하나만 수정한 뒤에 수정된 사용자와 수정하지 않은 사용자의 정보를 모두 확인하면 된다.
둘 다 적용하기에도 크게 귀찮지 않으니 둘 다 적용해보자.
public interface UserDao {
...
int update(User user);
}인터페이스에서 정수형을 반환하도록 바꾸고
@Override
public int update(User user) {
return this.jdbcTemplate.update(
"update users set name = ?, password = ?, level = ?, login_count = ?, recommend_count = ? "
, user.getName(), user.getPassword(), user.getLevel().intValue(), user.getLoginCount(), user.getRecommendCount()
);
}update() 메소드에서도 결과 int를 반환하도록 하자.
@Test
@DisplayName("사용자 수정 기능 테스트")
public void update() {
userDao.add(user1);
userDao.add(user2);
user1.setName("오민규");
user1.setPassword("2345");
user1.setLevel(Level.GOLD);
user1.setLoginCount(1000);
user1.setRecommendCount(999);
int updateCount = userDao.update(user1);
assertEquals(updateCount, 1);
User user1update = userDao.get(user1.getId());
checkSameUser(user1, user1update);
User user2same = userDao.get(user2.getId());
checkSameUser(user2, user2same);
}테스트도 새로 작성했다. user2는 데이터가 변화하지 않아야 한다.
일부러 where 문을 깜빡한 것처럼 테스트를 실행시키니
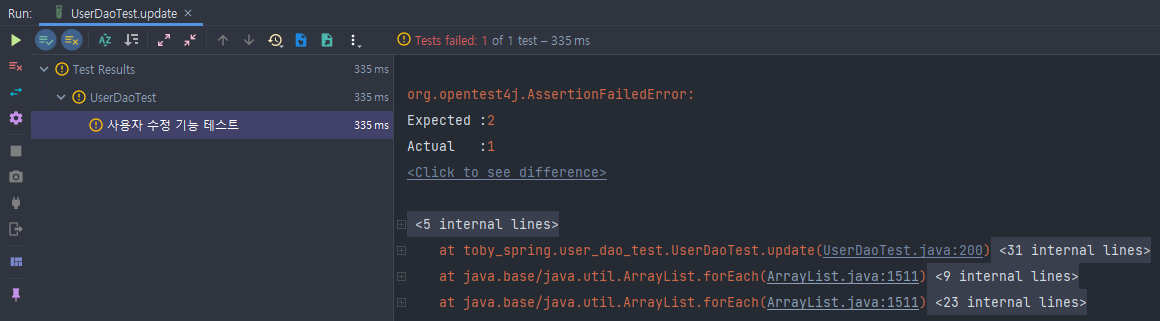
테스트에서 위와 같이 에러가 발생한다. updateCount에 대한 검증을 빼도
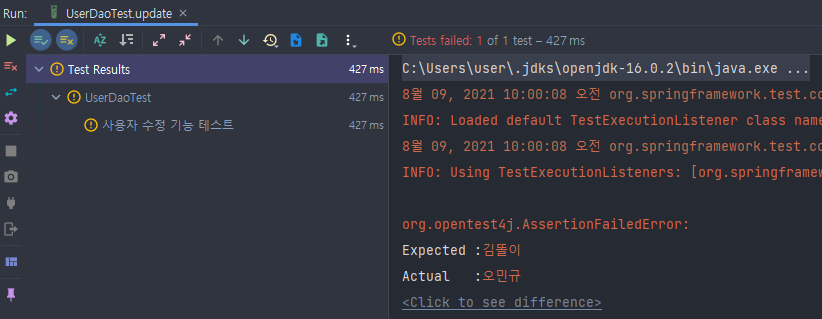
위와 같이 변하지 않아야 되는 데이터가 변해서 또 에러가 난다.
다시 where를 추가해주니,
정상적으로 테스트가 작동한다.
UserService.upgradeLevels()
이제 레벨 관리 기능을 추가해야 한다. 레벨 관리 기능은 특정한 시간마다 돌아가며 현재 이용중인 회원 중 레벨업 조건을 만족한 회원의 레벨을 업그레이드 해줄 것이다.
그렇다면 이 사용자 관리 로직은 어디에 두는 것이 좋을까? UserDaoJdbc는 적당하지 않다. DAO는 데이터를 어떻게 가져오고 조작할지 다루는 곳이지 비즈니스 로직을 두는 곳이 아니다. 사용자 관리 비즈니스 로직을 담을 클래스를 하나 추가해주자. 비즈니스 로직 서비스를 제공한다는 의미에서 클래스 이름은 UserService로 한다.
UserService는 User 도메인과 관련된 비즈니스 로직을 담당하게 되므로, User 객체의 내용과 DB에 있는 User의 내용을 모두 건드려야 한다. UserService는 UserDao 인터페이스 타입으로 userDao 빈을 DI받아서 쓸 것이다. 대문자로 시작하는 UserDao는 인터페이스 이름이고, 소문자로 시작하는 userDao는 빈 이름이니 잘 구분하자.
UserService는 UserDao의 구현 클래스가 변화해도 영향을 받으면 안된다. 데이터 액세스 로직이 바뀌었다고 해도 비즈니스 로직 코드를 수정하는 일이 있어선 안 된다. 따라서 DAO의 인터페이스를 사용하고 DI를 적용하자. DI를 적용하려면 당연히 UserSerivce도 스프링의 빈으로 등록돼야 한다.
아래와 같은 구조로 코드를 작성할 것이다.
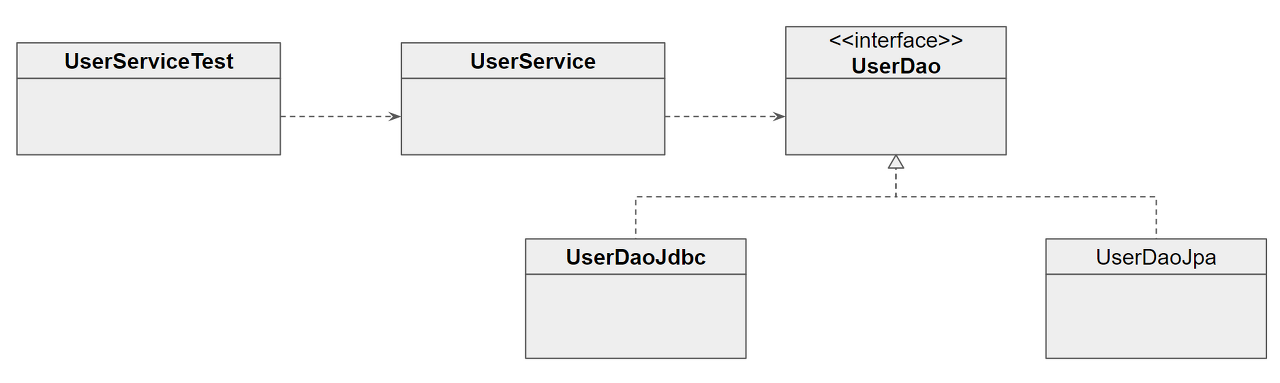
UserService 클래스와 빈 등록
public class UserService {
UserDao userDao;
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
}UserDao를 DI받을 수 있는 환경을 만들어놓았다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="dataSource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="username" value="postgres" />
<property name="password" value="iwaz123!@#" />
<property name="driverClass" value="org.postgresql.Driver" />
<property name="url" value="jdbc:postgresql://localhost/toby_spring" />
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userDao" class="toby_spring.user.dao.UserDaoJdbc">
<property name="jdbcTemplate" ref="jdbcTemplate" />
</bean>
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="userDao" ref="userDao" />
</bean>
</beans>위와 같이 userService를 빈으로 등록하고 userDao 빈을 userService에 주입해주자.
UserServiceTest 클래스
먼저 간단히 UserService가 정상적으로 userDao를 주입받는지만 확인해보자.
@ExtendWith(SpringExtension.class) // (JUnit5)
@ContextConfiguration(locations="/spring/applicationContext.xml")
class UserServiceTest {
@Autowired UserService userService;
@Test
@DisplayName("userDao를 정상적으로 주입받았는지 확인")
public void isUserDaoNotEmpty() {
Assertions.assertNotNull(userService.userDao);
}
}위와 같이 작성해주면, userService 내부에 있는 userDao가 null 인지 간단하게 확인할 수 있다.
upgradeLevels() 메소드
public void upgradeLevels() {
List<User> users = userDao.getAll();
for (User user : users) {
Boolean changed = null;
if (user.getLevel() == Level.BASIC && user.getLoginCount() >= 50) {
user.setLevel(Level.SILVER);
changed = true;
} else if (user.getLevel() == Level.SILVER && user.getRecommendCount() >= 30) {
user.setLevel(Level.GOLD);
changed = true;
} else if (user.getLevel() == Level.GOLD) {
changed = false;
} else {
changed = false;
}
if(changed) {
userDao.update(user);
}
}
}어쩌다가 위와 같은 메소드를 만들었다고 생각해보자. 중복된 코드는 좀 나오고 책임의 분리도 잘 안되어있지만 비즈니스 로직이 명확히 보이고 아마 제대로 동작할 것이다.
upgradeLevels() 테스트
모든 케이스를 체크하려면 각 레벨에서 업그레이드 되는 경우와 업그레이드 되지 않는 경우를 나눠서 생각해보면 된다.
레벨은 3가지가 있고 경우는 2가지가 있어서 총 6가지의 경우의 수가 나오는데, GOLD의 경우 더이상 다음 레벨이 없어 업그레이드가 불가능하니 총 5가지만 체크해보면 된다.
@BeforeEach
public void setUp() {
users = Arrays.asList(
new User("bumjin", "박범진", "p1", Level.BASIC, 49, 0)
, new User("joytouch", "강명성", "p2", Level.BASIC, 50, 0)
, new User("erwins", "신승한", "p3", Level.SILVER, 60, 29)
, new User("madnite1", "이상호", "p4", Level.SILVER, 60, 30)
, new User("green", "오민규", "p5", Level.GOLD, 100, 100)
);
}테스트 픽스쳐는 위와 같이 만들어주었다. loginCount는 50일 때 업그레이드 기준이고, recommendCount는 30일 때 업그레이드 기준이어서 일부러 기준의 경계값을 이용한 데이터를 만들었다.
보통 잘못된 현상이 발생할 때는 경계값 근처에서 많이 일어나므로, 경계값으로 테스트하는 습관은 좋은 습관이다. BASIC과 SILVER는 각각 업그레이드가 가능한 경우, 불가능한 경우 모든 경우의 수를 다 만들어주었다.
@Test
@DisplayName("사용자 레벨 업그레이드 테스트")
public void upgradeLevels() {
for (User user : users) {
userDao.add(user);
}
userService.upgradeLevels();
checkLevel(users.get(0), Level.BASIC);
checkLevel(users.get(1), Level.SILVER);
checkLevel(users.get(2), Level.SILVER);
checkLevel(users.get(3), Level.GOLD);
checkLevel(users.get(4), Level.GOLD);
}
private void checkLevel(User user, Level expectedLevel) {
User userUpdate = userDao.get(user.getId());
Assertions.assertEquals(userUpdate.getLevel(), expectedLevel);
}위와 같이 테스트를 작성하고 각각 데이터가 올바르게 레벨 업그레이드가 됐는지, GOLD인 경우 그대로인지를 확인했다.

테스트는 잘 통과한다.
UserService.add()
처음 가입하는 사용자는 기본적으로 BASIC 레벨이어야 한다는 요구사항을 충족시켜보자.
public void add(User user) throws DuplicateUserIdException {
try {
this.jdbcTemplate.update("insert into users(id, name, password, level, login_count, recommend_count) values (?, ?, ?, ?, ?, ?)"
, user.getId()
, user.getName()
, user.getPassword()
, user.getLevel().intValue()
, user.getLoginCount()
, user.getRecommendCount()
);
} catch (DuplicateKeyException e) {
throw new DuplicateUserIdException(e);
}
}현재는 단순히, 받은 Level을 적용시키도록 하고 있다. 그렇다면 저기에 그냥 만일 레벨 정보가 null이라면, Level.BASIC을 넣도록 할까? 그건 옳지 않을 것이다. UserDao는 온전히 데이터의 CRUD를 다루는 데만 치중하는 것이 옳고, 비즈니스 로직이 섞이는 것은 바람직하지 않다.
차라리 User 클래스에서 level 필드를 기본 값으로 Level.BASIC으로 초기화해보자. 하지만 처음 가입할 때를 제외하면 무의미한 정보인데, 단지 이 로직을 담기 위해 클래스에서 직접 초기화하는 것은 문제가 있어 보이긴 한다.
그렇다면 UserService에 이 로직을 넣으면 어떨까? UserDao의 add() 메소드는 사용자 정보를 담은 User 오브젝트를 받아서 DB에 넣어주는 데 충실한 역할을 한다면, UserService에도 add()를 만들어두고 사용자가 등록될 때 적용할만한 비즈니스 로직을 담당하게 하면 될 것이다.
UserDao와 같이 리포지토리 역할을 하는 클래스를 컨트롤러에서 바로 쓰냐 마냐에 대한 논쟁이 있는데, 바로 쓰면 아무런 비즈니스 로직이 들어가지 않은 순수한 CRUD의 의미일 것이다.
먼저 테스트부터 만들어보자. UserService의 add()를 호출하면 레벨이 BASIC으로 설정되는 것이다. 그런데, UserService의 add()에 전달되는 User 오브젝트에 Level 값이 미리 설정되어 있다면, 설정된 값을 이용하도록 하자.
그렇다면 테스트 케이스는 두가지 종류가 나올 수 있다.
- 레벨이 미리 설정된 경우
- 설정된 레벨을 따른다.
- 레벨이 미리 설정되지 않은 경우 (레벨이 비어있는 경우)
BASIC레벨을 갖는다.
각각 add() 메소드를 호출하고 결과를 확인하도록 만들자.
가장 간단한 방법은 UserService의 add() 메소드를 호출할 때 파라미터로 넘긴 User 오브젝트에 level 필드를 확인해보는 것이고, 다른 방법은 UserDao의 get() 메소드를 이용해서 DB에 저장된 User 정보를 가져와 확인하는 것이다. 두가지 다 해도 좋고, 후자만 해도 괜찮을 것 같다.
UserService는 UserDao를 통해 DB에 사용자 정보를 저장하기 때문에 이를 확인해보는 게 가장 확실한 방법이다. UserService가 UserDao를 제대로 사용하는지도 함께 검증할 수 있고, 디폴트 레벨 설정 후에 UserDao를 호출하는지도 검증되기 때문이다.
테스트코드 작성 및 UserService의 add 메소드
@Test
@DisplayName("기본 레벨이 Level.BASIC으로 설정되는지 테스트")
public void defaultLevelIsBasic() {
User userWithLevel = users.get(3); //SILVER
User userWithoutLevel = users.get(4);
userWithoutLevel.setLevel(null);
userService.add(userWithLevel);
userService.add(userWithoutLevel);
User dbUserWithLevel = userDao.get(userWithLevel.getId());
User dbUserWithoutLevel = userDao.get(userWithoutLevel.getId());
Assertions.assertEquals(dbUserWithLevel.getLevel(), userWithLevel.getLevel());
Assertions.assertEquals(dbUserWithoutLevel.getLevel(), Level.BASIC);
} public void add(User user) {
// 간단히 level이 null이라면, Level.BASIC 삽입
if(user.getLevel() == null) {
user.setLevel(Level.BASIC);
}
userDao.add(user);
}위 코드의 핵심은 기존에 픽스쳐에 존재하던 유저에 2개에 대해
- 하나는
level을null로 설정한 뒤에userService를 통해.add()하고level이BASIC인지 확인한다. - 다른 하나는
level을Level.SILVER인 상태 그대로userService를 통해.add()하여level이 그대로SILVER인지 확인한다.
테스트를 돌려보면 성공이고, 다만 테스트가 조금 복잡한 것이 흠이다. 간단한 비즈니스 로직을 담은 코드를 테스트하기 위해 DAO와 DB까지 모두 동원되는 점이 조금 불편하다. 이런 테스트는 깔끔하고 간단하게 만드는 방법이 있는데 뒤에서 다시 다뤄보자.
코드 개선
어느정도 요구사항은 맞춰놨지만, 아직 코드가 깔끔하지 않게 느껴진다. 다음 사항들을 체크해보자.
- 코드에 중복된 부분은 없는가?
- 코드가 무엇을 하는 것인지 이해하기 불편하진 않은가?
- 코드가 자신이 있어야 할 자리에 있는가
- 앞으로 변경이 일어날 수 있는 건 어떤 것이며, 그 변화에 쉽게 대응할 수 있게 작성 되었는가?
upgradeLevels() 메소드 코드의 문제점
public void upgradeLevels() {
List<User> users = userDao.getAll();
for (User user : users) {
Boolean changed = null;
if (user.getLevel() == Level.BASIC && user.getLoginCount() >= 50) {
user.setLevel(Level.SILVER);
changed = true;
} else if (user.getLevel() == Level.SILVER && user.getRecommendCount() >= 30) {
user.setLevel(Level.GOLD);
changed = true;
} else if (user.getLevel() == Level.GOLD) {
changed = false;
} else {
changed = false;
}
if(changed) {
userDao.update(user);
}
}
}for루프 속에 들어있는if/else블록이 겹쳐 읽기 불편하다.- 레벨의 변화 단계와 업그레이드 조건, 조건이 충족됐을 때 해야 할 작업이 섞여서 로직을 이해하기 어렵다.
- 플래그를 두고 이를 변경하고 마지막에 이를 확인해서 업데이트를 진행하는 방법도 그리 깔끔해보이지 않는다.
코드가 깔끔해보이지 않는 이유는 이렇게 성격이 다른 여러가지 로직이 섞여있기 때문이다.
user.getLevel() == Level.BASIC은 레벨이 무엇인지 파악하는 로직이다.user.getLoginCount() >= 50은 업그레이드 조건을 담은 로직이다.user.setLevel(Level.SILVER);는 다음 단계의 레벨이 무엇인지와 레벨 업그레이드를 위한 작업은 어떤 것인지가 함께 담겨있다.changed = true;는 이 자체로는 의미가 없고, 단지 멀리 떨어져 있는userDao.update(user);의 작업이 필요함을 알려주는 역할이다.
잘 살펴보면 관련이 있지만, 사실 성격이 조금 다른 것들이 섞여있거나 분리돼서 나타나는 구조다.
변경될만한 것 추측하기
- 사용자 레벨
- 업그레이드 조건
- 업그레이드 작업
- 사용자 레벨이 변경되면?
- 현재 if 조건 블록이 레벨 개수만큼 반복되고 있다. 새로운 레벨이 추가되면,
Level ENUM도 수정해야 하고,upgradeLevels()의 레벨 업그레이드 로직을 담은 코드에if조건식과 블록을 추가해줘야 한다.
- 현재 if 조건 블록이 레벨 개수만큼 반복되고 있다. 새로운 레벨이 추가되면,
- 업그레이드 작업이 변경되면?
- 추후에 레벨을 업그레이드 작업에서 이를테면 레벨 업그레이드 축하 알람 등 새로운 작업이 추가되면,
user.setLevel(다음레벨);뒤에 추가적인 코드를 작성해주어야 할 것이다. 그러면 점점 메소드의if문 블록은 커진다.
- 추후에 레벨을 업그레이드 작업에서 이를테면 레벨 업그레이드 축하 알람 등 새로운 작업이 추가되면,
- 업그레이드 조건이 변경되면?
- 업그레이드 조건도 문제다. 새로운 레벨이 추가되면 기존
if조건과 맞지 않으니else로 이동하는데, 성격이 다른 두 가지 경우가 모두 한 곳에서 처리되는 것은 뭔가 이상하다. - 업그레이드 조건이 계속 까다로워지면 마지막엔
if()내부에 들어갈 내용이 방대하게 커질 수 있다.
- 업그레이드 조건도 문제다. 새로운 레벨이 추가되면 기존
아마 upgradeLevels() 코드 자체가 너무 많은 책임을 떠안고 있어서인지 전반적으로 변화가 일어날수록 코드가 지저분해진다는 것을 추측할 수 있다. 지저분할수록 찾기 힘든 버그가 숨어들어갈 확률이 높아질 것이다.
upgradeLevels() 리팩토링
public void upgradeLevels() {
List<User> users = userDao.getAll();
for (User user : users) {
if(canUpgradeLevel(user)) {
upgradeLevel(user);
}
}
}위는 upgradeLevels()에서 기본 작업 흐름만 남겨둔 코드이다. 이 코드는 한 눈에 읽기에도 사용자 정보를 받아서 레벨 업그레이드를 할 수 있으면 레벨 업그레이드를 한다. 명확하다.
이는 구체적인 구현에서 외부에 노출할 인터페이스를 분리하는 것과 마찬가지 작업을 코드에 한 것이다.
이제 인터페이스화된 메소드들을 하나씩 구현해보자.
canUpgradeLevel()
private boolean canUpgradeLevel(User user) {
Level currentLevel = user.getLevel();
return switch(currentLevel) {
case BASIC -> user.getLoginCount() >= 50;
case SILVER -> user.getRecommendCount() >= 30;
case GOLD -> false;
default -> throw new IllegalArgumentException("Unknown Level: " + currentLevel);
};
}
canUpgradeLevel()의 요구사항은 해당 사용자에 대한 레벨 업그레이드 가능 여부를 확인하고 그 결과를 반환하는 것이다.
switch문으로 레벨을 구분하고 각 레벨에 대한 업그레이드 조건을 체크하고 업그레이드가 가능한지에 따라 true/false를 반환해준다.
또, 등록되지 않은 레벨에 대해 메소드를 수행할 시에는 IllegalArgumentException이 발생하기 때문에 해당 등급에 대한 로직 처리를 하지 않았음을 쉽게 알 수 있다.
upgradeLevel()
private void upgradeLevel(User user) {
Level currentLevel = user.getLevel();
switch (currentLevel) {
case BASIC -> user.setLevel(Level.SILVER);
case SILVER -> user.setLevel(Level.GOLD);
default -> throw new IllegalArgumentException("Can not upgrade this level: " + currentLevel);
}
userDao.update(user);
}
upgradeLevel()의 요구사항은 해당 사용자에 대한 레벨 업그레이드를 진행하는 것이다.
위와 같이 작성하여 보기엔 깔끔해 보이지만, 여기서도 무언가 맘에 안드는 점이 있다.
- 업그레이드된 다음 레벨이 무엇인지 자체를 이 메소드가 독립적으로 정하고 있다.
- 업그레이드 후의 작업이 늘어난다면? 지금은
level필드만을 손보지만, 나중에 포인트 같은 개념이 생겨서 레벨 업그레이드 보너스 포인트 같은 것을 증정해야된다고 생각해보자.case문 뒤의 블록 내용이 많이 늘어날 것이다.
업그레이드 후의 레벨이 무엇인지 결정하는 책임은 Level ENUM이 갖는 것이 맞지 않을까? 레벨의 순서에 대한 책임을 UserService에게 위임하지 말자.
Level enum
public enum Level {
// 초기화 순서를 3, 2, 1 순서로 하지 않으면 `SILVER`의 다음 레벨에 `GOLD`를 넣는데 에러가 발생한다.
GOLD(3, null), SILVER(2, GOLD), BASIC(1, SILVER);
private final int value;
private final Level next;
Level(int value, Level next) {
this.value = value;
this.next = next;
}
public Level nextLevel() {
return next;
}
public int intValue() {
return value;
}
public static Level valueOf(int value) {
return switch (value) {
case 1 -> BASIC;
case 2 -> SILVER;
case 3 -> GOLD;
default -> throw new AssertionError("Unknown value: " + value);
};
}
}위와 같이 업그레이드 순서에 대한 책임을 Level enum에 맡겼다. 이제 다음 레벨이 무엇인지 알고 싶다면, .nextLevel() 메소드를 출력해보면 된다. 이제 다음 단계의 레벨이 무엇인지 일일이 if문에 담아둘 필요가 없다.
이제 사용자 정보가 바뀌는 부분을 UserService 메소드에서 User로 옮겨보자. User는 사용자 정보를 담고 있는 단순한 자바빈이긴 하지만 User도 엄연히 자바 오브젝트이고 내부 정보를 다루는 기능이 있을 수 있다. UserService가 일일이 레벨 업그레이드 시에 User의 어떤 필드를 수정해야 하는지에 대한 로직을 갖고 있기 보다는 User에게 레벨 업그레이드를 해야 하니 정보를 변경하라고 요청하는 편이 낫다.
public void upgradeLevel() {
Level nextLevel = this.level.nextLevel();
if (nextLevel == null) {
throw new IllegalStateException(this.level + "은 업그레이드가 불가능합니다.");
} else {
this.level = nextLevel;
}
}UserService의 canUpgradeLevel() 메소드에서 업그레이드 가능 여부를 미리 판단해주긴 하지만, User 오브젝트를 UserService만 사용한다는 보장은 없으므로, 스스로 예외상황에 대한 검증 기능을 갖고 있는 편이 안전하다.
Level enum은 다음 레벨이 없는 경우에는 nextLevel()에서 null을 반환한다. 따라서 이 경우에는 User의 레벨 업그레이드 작업이 진행돼서는 안되므로, 예외를 던져야 한다.
애플리케이션의 로직을 바르게 작성하면 이런 경우는 아예 일어나지 않겠지만, User 오브젝트를 잘못 사용하는 코드가 있다면 확인해줄 수 있으니 유용하다.
User에 업그레이드 작업을 담당하는 독립적인 메소드를 두고 사용할 경우, 업그레이드 시 기타 정보도 변경이 필요해졌을 때, 그 장점이 무엇인지 알 수 있을 것이다. 이를테면 마지막으로 업그레이드 된 시점을 기록하고 싶다면, lastUpgraded 필드를 추가하고 this.lastUpgraded = new Date();와 같은 코드를 추가함으로써, 쉽게 동작을 더할 수 있다.
UserService.upgradeLevel()
private void upgradeLevel(User user) {
user.upgradeLevel();
userDao.update(user);
}User 객체에 레벨을 업그레이드 하는 책임을 주어 코드가 한결 깔끔해졌다. 이전의 if문이 많이 들어있던 코드를 생각하면, 간결하고 작업 내용이 명확하게 드러난다. 각 오브젝트가 해야 할 책임도 깔끔하게 분리됐다.
지금 개선한 코드를 전체적으로 살펴보면, 각 오브젝트와 메소드가 각각 자기 몫의 책임을 맡아 일을 하는 구조로 만들어졌음을 알 수 있을 것이다.
UserService, User, Level이 내부 정보를 다루는 자신의 책임에 충실한 기능을 갖고 있으면서 필요가 생기면 이런 작업을 수행해달라고 서로 요청하는 구조이다.
각자 자기 책임에 충실한 작업만 하고 있으니 코드를 이해하기도 쉽다. 또, 변경이 필요할 때 어디를 수정해야 할지도 쉽게 알 수 있다. 잘못된 요청이나 작업을 시도했을 때 이를 확인하고 예외를 던져줄 준비도 다 되어 있다.
각각을 독립적으로 테스트하도록 만들면 테스트 코드도 단순해진다.
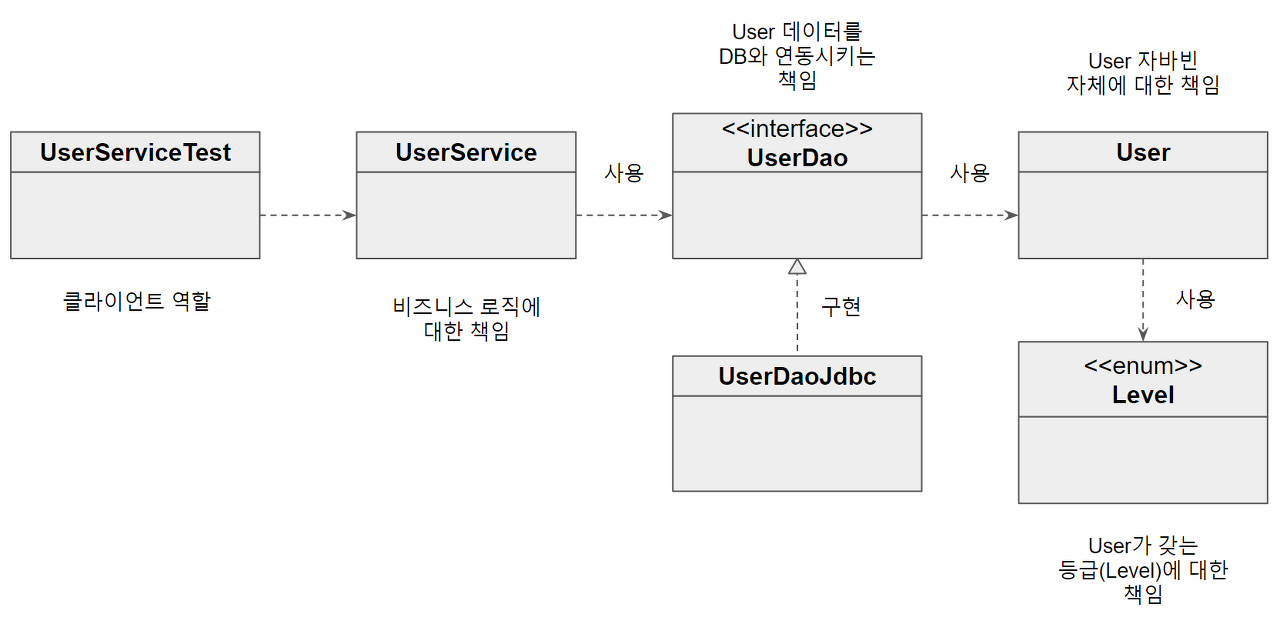
각 클래스가 자신이 갖는 책임에 대한 코드만 작성하도록 노력했다.
객체지향적인 코드는 다른 오브젝트의 데이터를 가져와서 작업하는 대신 데이터를 갖고 있는 다른 오브젝트에게 작업을 해달라고 요청한다.오브젝트에게 데이터를 요구하지 말고 작업을 요청하라는 것이 객체지향 프로그래밍의 가장 기본이 되는 원리이기도 하다.
처음 구현했던 UserService의 upgradeLevels() 메소드는 User 오브젝트에서 데이터를 가져와서 그것을 가지고 User 오브젝트나 Level enum이 해야 할 작업을 대신 수행하고 직접 User 오브젝트의 데이터를 변경해버렸다. 이보다는 UserService는 User에게 레벨 업그레이드 작업을 해달라고 요청하고, 또 User는 Level에게 다음 레벨이 무엇인지 알려달라고 요청하는 방식으로 동작하게 하는 것이 바람직하다.
만일,
BRONZE레벨을BASIC과SILVER사이에 추가하라.BRONZE에서SILVER로 업그레이드하는 조건은 로그인 횟수 80번이다.
보자마자 Level enum에 있는 다음 레벨과 관련된 코드와 UserService에 있는 canUpgradeLevel() 메소드를 떠올릴 수 있다면 성공적일 것 같다.
- 가장 최근의 레벨 변경 날짜를 저장해두어라.
- 레벨 변경 시 콘솔에 로그를 남기도록 하라.
위와 같은 요구사항이 들어오면 먼저 레벨 변경은 User의 upgradeLevel() 메소드에서 수행하는 것이니 User의 필드에 최근 레벨 변경 날짜를 추가하고 lastLevelUpdated = new LocalDateTime() 등의 코드를 추가하는 것으로 해결할 수 있을 것이다.
로그를 남기는 것은 User의 상태와는 전혀 관련이 없으니 UserService의 upgradeLevel()에서 DB 업데이트 이후에 것이 바람직할 것이다.
이렇게 책임에 맞게 코드를 작성하면 변경 후에도 코드는 여전히 깔끔하고 코드를 이해하는데도 어려움이 없을 것이다.
물론 지금까지 진행한 UserService의 리팩토링과 그 결과로 만들어진 코드가 정답이라거나 완벽한 것은 아니다. 애플리케이션의 특성과 구조, 발전 방향 등에 따라 더 세련된 설계도 가능하다. 좀 더 객체지향 적인 특징이 두드러지게 구조를 바꿀 수도 있다. 현재 UserService의 코드는 5장에서 설명하려는 스프링의 기능을 적용하기 적절한 구조로 만들어둔 것 뿐이다.
항상 코드를 더 깔끔하고 유연하면서 변화에 대응하기 쉽고 테스트하기에 좋게 만드려고 노력해야 함을 기억하고 다음으로 넘어가자.
User 테스트
방금 User에 간단하지만 로직을 담은 메소드를 추가했다. 앞으로도 계속 새로운 기능과 로직이 추가될 가능성이 있으니 테스트를 만들어두자.
@Test
@DisplayName("유저 레벨 업그레이드 테스트")
public void upgradeLevel() {
Level[] levels = Level.values();
for (Level level : levels) {
if(level.nextLevel() == null) continue;
user.setLevel(level);
user.upgradeLevel();
Assertions.assertEquals(user.getLevel(), level.nextLevel());
}
}
@Test
@DisplayName("예외 테스트 - 다음 레벨이 없는 레벨을 업그레이드 하는 경우")
public void cannotUpgradeLevel() {
Level[] levels = Level.values();
Assertions.assertThrows(IllegalStateException.class, () -> {
for (Level level : levels) {
if(level.nextLevel() != null) continue;
user.setLevel(level);
user.upgradeLevel();
}
});
}- 유저 레벨이 잘 업그레이드 되는지
- 업그레이드 불가능한 레벨을 업그레이드 했을 때 예외처리가 잘 되는지
두가지에 대한 테스트를 해봤다.
핵심은 User 클래스를 테스트할 때는 딱히 스프링 프레임워크에 대한 의존성이 없어서 스프링 테스트가 아닌 간단한 유닛테스트로 테스팅을 진행할 수 있다는 점이다.
굳이 이렇게 까지 테스트를 하는 이유는 나중에 있을 변화에 대비하기 위해서이다. 나중에 upgradeLevel() 메소드에 좀 더 복잡한 기능이 추가됐을 때도 이 테스트를 확장해 사용할 수 있다.
UserServiceTest 개선
기존에는 다음 레벨에 대한 정보를 Level.nextLevel()에서 가져오는 것이 아니라, 직접 Level.SILVER와 같은 방식으로 넣어주었다. 이러한 사소한 것도 사실 중복이다.
@Test
@DisplayName("사용자 레벨 업그레이드 테스트")
public void upgradeLevels() {
for (User user : users) {
userDao.add(user);
}
userService.upgradeLevels();
checkLevel(users.get(0), Level.BASIC);
checkLevel(users.get(1), Level.SILVER);
checkLevel(users.get(2), Level.SILVER);
checkLevel(users.get(3), Level.GOLD);
checkLevel(users.get(4), Level.GOLD);
}위와 같이 각각의 User에 대해 checkLevel()에 Level을 직접 넣어준 것을 볼 수 있다. 레벨이 변경되거나 추가되면 테스트도 따라서 수정해주어야 했다.
@Test
@DisplayName("사용자 레벨 업그레이드 테스트")
public void upgradeLevels() {
for (User user : users) {
userDao.add(user);
}
userService.upgradeLevels();
checkLevelUpgraded(users.get(0), false);
checkLevelUpgraded(users.get(1), true);
checkLevelUpgraded(users.get(2), false);
checkLevelUpgraded(users.get(3), true);
checkLevelUpgraded(users.get(4), false);
}
private void checkLevelUpgraded(User userOrigin, boolean upgraded) {
User userUpdate = userDao.get(userOrigin.getId());
Assertions.assertEquals(
userOrigin.getLevel().nextLevel() == userUpdate.getLevel()
, upgraded);
}위와 같이 테스트를 변경했다. 다음 레벨이 무엇인지에 대한 책임은 Level에서 담당하고, 우리는 그 부분을 더이상 하드코딩하지 않는다.
checkLevel() 메소드의 파라미터도 upgraded로 바뀌어 단순히 업그레이드 되었는지를 판단하고, 정확히 다음 레벨이 어떤 레벨인지는 Level enum에게 맡긴다.
또한 레벨이 업그레이드 되는지에 대해서만 관심을 가지므로 메소드명도 명확하게 바꾸고, 업그레이드가 되는지 안되는지에 대해 확실히 true/false로 구분했다.
의미없는 상수 중복 제거
private boolean canUpgradeLevel(User user) {
Level currentLevel = user.getLevel();
return switch(currentLevel) {
case BASIC -> user.getLoginCount() >= 50;
case SILVER -> user.getRecommendCount() >= 30;
case GOLD -> false;
default -> throw new IllegalArgumentException("Unknown Level: " + currentLevel);
};
}...
new User("bumjin", "박범진", "p1", Level.BASIC, 49, 0)
, new User("joytouch", "강명성", "p2", Level.BASIC, 50, 0)
...위의 50이 의미하는 것은 정확히 말하면 BASIC 레벨 유저가 SILVER 레벨이 되기 위해서 필요한 로그인 횟수이다. 현재 상황에서는 SILVER 레벨이 되기 위해 필요한 로그인 횟수에 변경이 생기면 둘 다 바꿔줘야 한다. 또 이렇게 의미론적으로도 불명확한 상수는 리팩토링해주자.
public class UserService {
UserDao userDao;
public static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
public static final int MIN_RECOMMEND_COUNT_FOR_GOLD = 30;
...
private boolean canUpgradeLevel(User user) {
Level currentLevel = user.getLevel();
return switch(currentLevel) {
case BASIC -> user.getLoginCount() >= MIN_LOGIN_COUNT_FOR_SILVER;
case SILVER -> user.getRecommendCount() >= MIN_RECOMMEND_COUNT_FOR_GOLD;
case GOLD -> false;
default -> throw new IllegalArgumentException("Unknown Level: " + currentLevel);
};
}
}import static toby_spring.user.service.UserService.*;
class UserServiceTest {
@Autowired UserService userService;
UserDao userDao;
List<User> users;
@BeforeEach
public void setUp() {
this.userDao = this.userService.userDao;
userDao.deleteAll();
users = Arrays.asList(
new User("bumjin", "박범진", "p1", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER - 1, 0)
, new User("joytouch", "강명성", "p2", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER, 0)
, new User("erwins", "신승한", "p3", Level.SILVER, MIN_LOGIN_COUNT_FOR_SILVER, MIN_RECOMMEND_COUNT_FOR_GOLD - 1)
, new User("madnite1", "이상호", "p4", Level.SILVER, MIN_LOGIN_COUNT_FOR_SILVER, MIN_RECOMMEND_COUNT_FOR_GOLD)
, new User("green", "오민규", "p5", Level.GOLD, 100, 100)
);
}
...위와 같이 픽스처에 들어가는 숫자들도 상수로 다 바꿔주었다. 이제 해당 상수만 조정하면 SILVER 레벨이 되기 위한 로그인 횟수를 테스트까지 한번에 조정할 수 있다. 의미론적으로도 훨씬 명확하다.
좀 더 욕심을 내자면 레벨을 업그레이드하는 정책을 유연하게 변경할 수 있도록 개선하는 것도 생각해볼 수 있다. 연말 이벤트나 새로운 서비스 홍보기간 중에는 렙레업그레이드 정책을 다르게 적용할 필요가 있을 수도 있다.
그럴 때마다 중요한 사용자 관리 로직을 담은 UserService의 코드를 직접 수정했다가 이벤트 기간이 끝나면 다시 이전 코드로 수정하는 것은 상당히 번거롭고 위험한 방법이다.
이런 경우 업그레이드 정책을 UserService에서 분리하는 방법을 고려할 수 있다. 분리된 업그레이드 정책을 담은 오브젝트는 DI를 통해 UserService에 주입한다.
스프링 설정을 통해서 평상시 정책을 구현한 클래스를 UserService에서 사용하게 하다가 이벤트 때는 새로운 업그레이드 정책을 담은 클래스를 따로 만들어서 DI해주면 된다. 이벤트가 끝나면 기존 업그레이드 정책 클래스로 다시 변경해준다.
public interface UserLevelUpgradePolicy {
boolean canUpgradeLevel(User user);
void upgradeLevel(User user);
}public class OrdinaryUserLevelUpgradePolicy implements UserLevelUpgradePolicy {
public OrdinaryUserLevelUpgradePolicy() {
}
@Override
public boolean canUpgradeLevel(User user) {
Level currentLevel = user.getLevel();
return switch(currentLevel) {
case BASIC -> user.getLoginCount() >= UserService.MIN_LOGIN_COUNT_FOR_SILVER;
case SILVER -> user.getRecommendCount() >= UserService.MIN_RECOMMEND_COUNT_FOR_GOLD;
case GOLD -> false;
default -> throw new IllegalArgumentException("Unknown Level: " + currentLevel);
};
}
@Override
public void upgradeLevel(User user) {
user.upgradeLevel();
}
}public class EventUserLevelUpgradePolicy implements UserLevelUpgradePolicy {
private final int bonusCount;
public EventUserLevelUpgradePolicy() {
this.bonusCount = 10;
}
public EventUserLevelUpgradePolicy(int bonusCount) {
this.bonusCount = bonusCount;
}
@Override
public boolean canUpgradeLevel(User user) {
Level currentLevel = user.getLevel();
return switch(currentLevel) {
case BASIC -> user.getLoginCount() + bonusCount >= UserService.MIN_LOGIN_COUNT_FOR_SILVER;
case SILVER -> user.getRecommendCount() + bonusCount >= UserService.MIN_RECOMMEND_COUNT_FOR_GOLD;
case GOLD -> false;
default -> throw new IllegalArgumentException("Unknown Level: " + currentLevel);
};
}
@Override
public void upgradeLevel(User user) {
user.upgradeLevel();
}
}책에는 나와있지 않지만, 위와 같은 형태로 작성해보았다.
테스트도 무난히 잘 통과하고 실패한다. 이벤트의 경우에는 10번의 카운트를 보너스로 줬기 때문에 실패해야 정상이다.
트랜잭션 서비스 추상화
사용자 레벨 작업의 특징은 사용자 데이터를 '1개씩' 조회 후에 조건에 맞는 사용자를 '1개씩' 업데이트하는 것이다.
여기서 중요한 건 '1개씩' 이라는 키워드인데 그렇다면 1000개의 데이터 중 애매하게 237개의 데이터까지 업데이트 되다가 238번째 데이터를 업데이트 하려는 순간 회사에 있던 MBC뉴스 기자가 차단기를 내려 정전이 일어나 컴퓨터가 종료되면 어떻게 될까?
현재까지의 로직으로는 237번째 데이터까지는 이미 업그레이드 된 상태이고, 238번째 데이터부터 다시 시작해야 할 것이다.
만일 은행과 같이 실제 돈을 다루는 곳에서 위와 같은 일이 일어나면 대형사고일 것이다. 누군가는 돈을 지급받고 누군가는 지급받지 못하는 현상이 발생했기 때문이다. 어떤 고객은 이를 차별대우로 느낄 수도 있다.
차라리 아예 데이터를 업데이트 안 된 깨끗한 상태로 유지하고 상황이 안정화 된 이후에 다시 데이터 업데이트를 시도하는 편이 좋을 것이다.
모 아니면 도
이번에는 테스트 과정 중 위에서 설명했던 정전과 같은 사고를 재현해야 한다. 그런데 실제 전원 선을 뽑으며 테스트할 수는 없으니 네트워크 에러 등이 발생했다고 가정하고 예외를 던져보자.
테스트용 UserService 대역
그런데 어떻게 예외를 만들어야 할까? 기존에 잘 돌아가던 코드 중간에 테스트를 위해 잠시 예외를 넣어야 할까? 테스트를 위해 기존에 잘 되던 코드를 건드리는 것은 좋은 생각은 아니다.
이런 경우에는 테스트 용으로 UserService의 대역을 만들어서 사용해보자. UserService의 코드를 복사 붙여넣기 하진 말고, 일단 상속을 받아서 변경이 필요한 메소드 부분만 오버라이드 하자.
테스트에서만 사용할 클래스라면 번거롭게 파일을 따로 만들지 말고 테스트 클래스 내부에 스태틱 클래스로 간편하게 만들어보자. 그런데 상속을 받는다고 해도 private으로 작성된 부분은 오버라이드 할 수 없으니, 기존 코드를 변경하는 게 조금 꺼림칙하긴 하지만 protected로 잠시만 변경하자.
static class TestUserService extends UserService {
private final String targetUserId;
public TestUserService(String targetUserId) {
this.targetUserId = targetUserId;
}
@Override
protected void upgradeLevel(User user) {
if(user.getId().equals(targetUserId)) {
throw new TestUserServiceException();
}
super.upgradeLevel(user);
}
static class TestUserServiceException extends RuntimeException {
}
}이 테스트용 클래스는 생성할 때 targetUserId를 받아서 해당 유저가 발견되었을 때 예외를 던진다.
@Test
@DisplayName("업데이트 도중 예외가 발생했을 때 전부 업데이트가 취소되는지 테스트")
public void upgradeAllOrNothing() {
// 먼저 등록
for (User user : users) {
userDao.add(user);
}
// "joytouch" -> SILVER, "madnite1" -> GOLD
// 두 유저는 각각 업그레이드 조건을 충족한 유저들이다.
// "madnite1"에서 예외를 발생시켰을 때,
// "joytouch"도 업그레이드가 되지 않은 원래 상태여야 테스트가 성공한다.
User joytouch = users.get(1);
User madnite1 = users.get(3);
TestUserService testUserService = new TestUserService(madnite1.getId());
testUserService.setUserDao(userDao);
testUserService.setUserLevelUpgradePolicy(userService.getUserLevelUpgradePolicy());
Assertions.assertThrows(TestUserService.TestUserServiceException.class, () -> {
testUserService.upgradeLevels();
});
// 업데이트 후에 DB에서 가져온 정보
User joytouchDb = userDao.get(joytouch.getId());
User madnite1Db = userDao.get(madnite1.getId());
System.out.println("joytouch = " + joytouch.getLevel());
System.out.println("joytouchDb = " + joytouchDb.getLevel());
System.out.println("madnite1 = " + madnite1.getLevel());
System.out.println("madnite1Db = " + madnite1Db.getLevel());
Assertions.assertEquals(joytouch.getLevel(), joytouchDb.getLevel());
Assertions.assertEquals(madnite1.getLevel(), madnite1Db.getLevel());
}테스트는 위와 같이 생성했다. 기존 픽스쳐에 등록된 유저 중 joytouch 라는 아이디를 가진 유저와 madnite1이라는 아이디를 가진 유저는 조건을 충족하여 각각 업그레이드의 대상이다.
그런데 만일 madnite1이라는 유저를 업그레이드 하다 중간에 예외가 발생하면, joytouch도 업그레이드 되지 않은 상태를 유지하고 있어야 한다.
기존에 가지고 있는 픽스쳐와 DB에서 불러온 데이터를 비교하여 확실히 업그레이드가 되지 않았는지 검증한다.
현재는 예상대로 테스트가 실패한다. 테스트가 성공하도록 만들어보자.
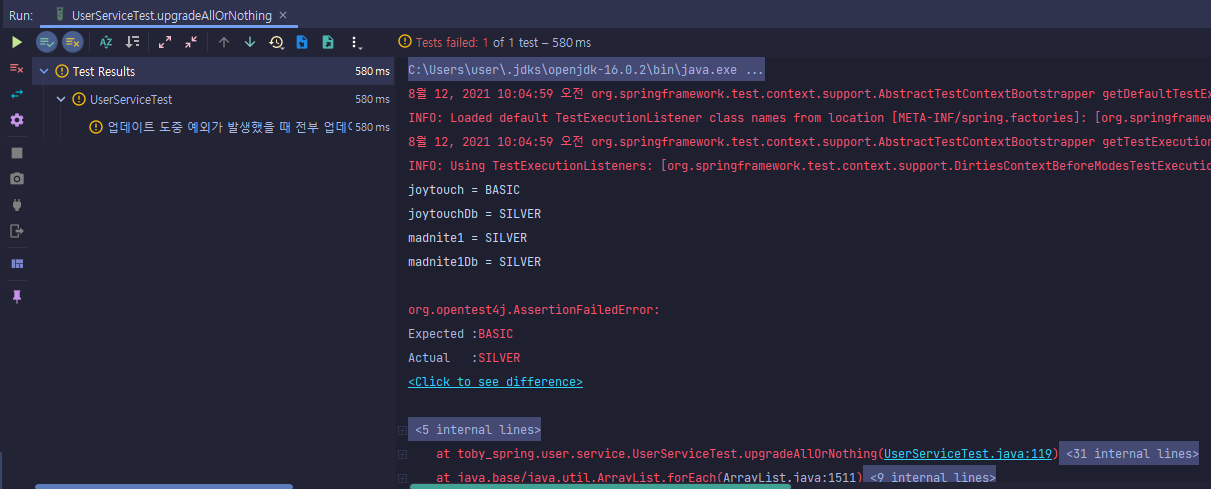
중간에 예외가 발생했지만, joytouch는 업데이트된 상태이다. 우리가 원하는 동작은 예외 때문에 하나라도 업데이트 하지 못하면, 모든 데이터가 업데이트 되지 않은 상태 그대로 유지되는 것이다.
테스트 실패의 원인
DB와 JDBC에 익숙하다면 이러한 원인이 트랜잭션에 있다는 것을 알 수 있다. upgradeLevels() 메소드에서 일어나는 모든 업데이트를 하나의 작업단위인 원자성을 가진 트랜잭션 안에 넣어야 하는데 이를 만족하지 못하는 것이다.
트랜잭션의 경계 설정
DB는 사실 그 자체로 완벽한 트랜잭션을 지원한다. 우리가 SQL 명령어로 다수의 ROW를 건드렸을 때, 하나의 ROW에만 반영되고 나머지 ROW에는 SQL 명령이 들어가지 않는 경우를 본 적이 없을 것이다. 하나의 SQL명령을 처리하는 경우에는 DB가 트랜잭션을 보장해준다고 믿을 수 있다.
하지만 지금의 경우처럼 여러 개의 SQL 명령을 하나의 트랜잭션으로 취급해야 하는 경우도 있다.
이를테면, 은행 계좌에서 누군가 돈을 송금했다면, 입금 계좌의 돈은 늘어나야 하고 출금 계좌의 돈은 줄어들어야 한다. 어느 한 계좌에만 입금 혹은 출금이 적용되는 것은 말도 안 된다.
만일 입금 계좌에 돈을 늘렸는데 예외가 발생했다면, 모든 작업을 취소시켜야 하는데 이를 트랜잭션 롤백(transaction rollback)이라고 한다.
반대로 하나의 트랜잭션의 모든 작업이 정상적으로 이루어졌다면 트랜잭션 커밋(transaction commit)을 적용해서 작업을 확정시켜야 한다.
JDBC 트랜잭션의 트랜잭션 경계 설정
트랜잭션은 시작 지점과 끝 지점이 있다. 시작 지점의 위치는 한 곳이며, 끝 지점의 위치는 두 곳이다. 끝날 때는 롤백되거나 커밋될 수 있다. 애플리케이션 내에서 트랜잭션이 시작되고 끝나는 위치를 트랜잭션의 경계라고 부른다. 복잡한 로직 흐름 사이에서 정확하게 트랜잭션 경계를 설정하는 일은 매우 중요하다.
Connection c = dataSource.getConnection();
c.setAutoCommit(false); // 트랜잭션 경계 시작
try {
PreparedStatement st1 =
c.prepareStatement("update users ...");
st1.executeUpdate();
PreparedStatement st2 =
c.prepareStatement("delete users ...");
st2.executeUpdate();
c.commit(); // 트랜잭션 경계 끝지점 (커밋)
} catch(Exception e) {
c.rollback(); // 트랜잭션 경계 끝지점 (롤백)
}
c.close();JDBC의 트랜잭션은 위의 소스처럼 Connection 객체를 통해 일어난다. c.setAutoCommit(false)를 호출하는 순간 트랜잭션 경계가 시작되며, c.commit() 혹은 c.rollback()을 호출하는 순간 트랜잭션 경계가 끝난다.
autoCommit의 기본 값은 true여서 원래는 작업마다 커밋이 자동으로 이뤄지는데 이 설정값을 false로 만듦으로써 커밋을 수동으로 이뤄지게 만들어 commit() 혹은 rollback()으로 끝내는 원리이다.
이렇게 트랜잭션 영역을 만드는 일을 트랜잭션 경계 설정이라고 한다. 이렇게 하나의 DB 커넥션 안에서 만들어지는 트랜잭션을 로컬 트랜잭션(local transaction)이라고도 한다. 2개 이상의 DB에서 만들어지는 트랜잭션은 글로벌 트랜잭션(global transaction)이라고 한다.
UserService와 UserDao의 트랜잭션 문제
현재까지 만든 코드에는 어디에도 트랜잭션을 설정하는 부분이 없었을 뿐더러 스프링에서 제공하는 JdbcTemplate 객체를 이용한 뒤로는 Connection 객체도 본적이 없다.
JdbcTemplate은 이전에 우리가 작성해보았던 JdbcContext와 동작이 비슷한데, 템플릿 메소드 안에서 DataSource의 getConnection() 메소드를 호출해서 Connection 오브젝트를 가져오고 작업을 마치면 Connection을 닫아주고 템플릿 메소드를 빠져나오는 것이다.
이전에 트랜잭션 경계 설정은 Connection에서 setAutoCommit(false)를 호출해야 만들어지는 것을 배웠는데 JdbcTemplate은 지금까지 우리가 이해한대로 라면 그냥 .update()나 .queryForObject()와 같은 메소드로 SQL문을 한번 실행할 때마다 1번의 트랜잭션을 가졌다가 자동으로 커밋된다고 볼 수 있다.
그렇다면 이전에 우리가 작성한 테스트에서도 각각의 사용자를 업데이트할 때 하나의 트랜잭션이 생겼다가 다시 사라지는 것이므로 총 5개의 트랜잭션이 생겼다가 사라지며 각각 결과를 적용하니 당연히 4번째 사용자를 수정하다가 예외가 발생해도 2번째 사용자의 업그레이드 트랜잭션은 이미 끝난 상태라 예외가 발생했을 때 이미 결과가 적용된 상태인 것이다.
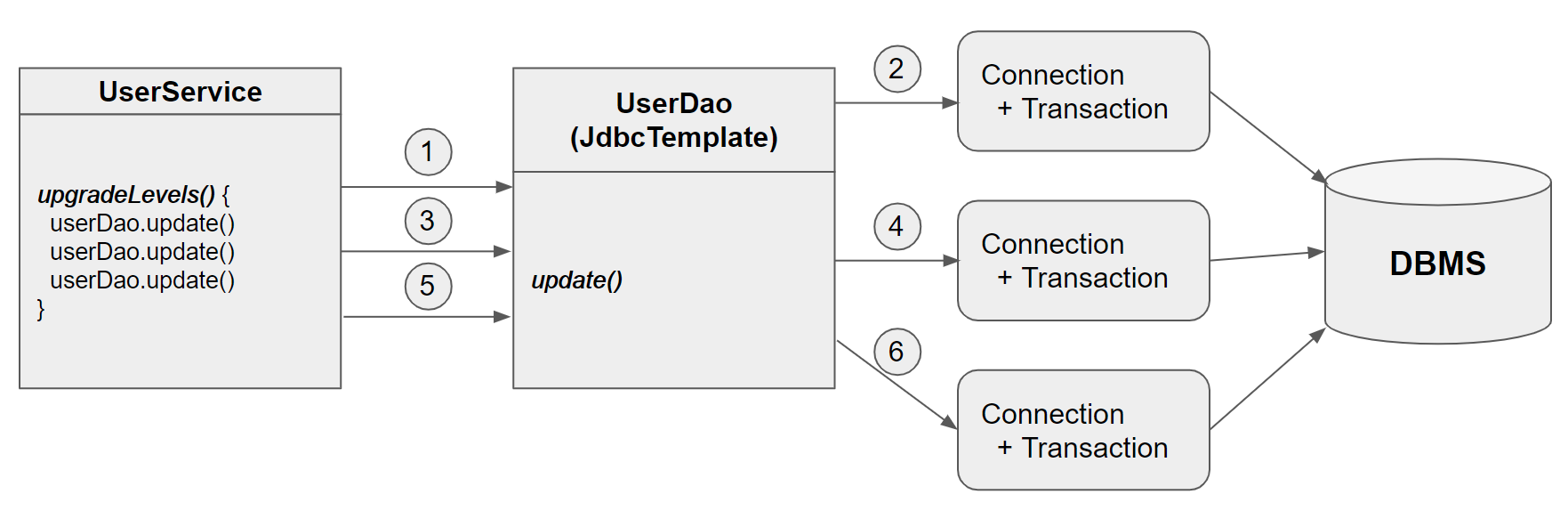
3번의 업데이트가 발생하는 경우, upgradeLevels()에서 3번의 userDao.update()를 호출하게 되고, userDao의 update()는 결국 jdbcTemplate.update()를 호출하게 된다. 그리고 jdbcTemplate의 update()는 각각 커넥션과 트랜잭션을 만들어내고 디비에 반영한다.
데이터 액세스 코드를 DAO로 분리했을 때는 결국 이처럼 DAO 메소드를 하나씩 호출할 때마다 하나의 새로운 트랜잭션이 만들어지는 구조가 될 수 밖에 없다.
그렇다면 upgradeLevels()와 같이 여러번 DB에 업데이트를 해야 하는 작업을 하나의 트랜잭션으로 만들려면 어떻게 해야 할까? DB 커넥션을 하나만 써야 한다. 그러나 현재는 UserService에서 DB 커넥션을 다룰 수 있는 방법이 없다.
비즈니스 로직 내의 트랜잭션 경계 설정
그렇다면 커넥션을 하나만 쓰기 위해 UserService에 있는 upgradeLevels()메소드를 커넥션을 다루고 있는 UserDao안으로 옮겨보면 어떨까? 이 방식은 비즈니스 로직과 데이터 로직을 한데 묶어버리는 한심한 결과를 초래한다. 지금까지 성격과 책임이 다른 코드를 분리하고 느슨하게 연결해서 확장성을 좋게 하려고 많은 수고를 해왔는데, 여기서 트랜잭션 문제를 해결한답시고 JDBC API와 User의 업그레이드 정책을 담은 코드를 뒤죽박죽으로 만드는 건 도저히 용납할 수 없다.
이 문제를 해결하기 위해 차라리 UserDao는 같은 책임을 지고 있고 UserService 내부에 잠시 트랜잭션을 위한 최소한의 코드만 가져오는 방법을 이용해서 해결해보자.
public void upgradeLevels() throws Exception {
// (1) DB Connection 생성
// (2) 트랜잭션 시작
try {
// (3) DAO 메소드 호출
// (4) 트랜잭션 커밋
}
catch(Exception e) {
// (5) 트랜잭션 롤백
throw e;
}
finally {
// (6) DB Connection 종료
}
}위 코드는 일반적인 트랜잭션을 사용하는 JDBC 코드의 구조이다. 그런데, 여기서 생성되는 Connection 오브젝트는 책임 관계로 볼 때 UserDao에 있는게 올바르다. 순수한 데이터 엑세스 로직은 UserDao에 가는 것이 옳기 때문이다.
그런데 최소한의 코드만을 이용해서 UserService에서 트랜잭션을 구현해보기로 했으니, UserService에서 Connection을 만들고 트랜잭션 경계를 설정(c.setAutoCommit(false))한 뒤에 해당 Connection을 UserDao로 넘기는 방식으로 트랜잭션을 만들어볼 것이다.
이를 위해 UserDao의 인터페이스는 다음과 같이 변경되어야 한다.
public interface UserDao {
public void add(Connection c, User user);
public User get(Connection c, String id);
...
public void update(Connection c, User user);
}이정도까지만 하면 될 것 같지만, upgradeLevels()는 직접 userDao.update()를 호출하는 것이 아니라 레벨 업그레이드가 가능한 User에 대해서만 upgradeLevel() 메소드를 통해 업그레이드 해준다. 그래서 upgradeLevels()에서 생성한 Connection을 upgrade

Level()로 넘기고 그 Connection을 다시한번 UserDao가 받아야 한다.
Connection 객체는 2번에 걸쳐 흘러가야 한다. 이렇게 Connection 오브젝트를 전달해서 사용하면, UserService의 upgradeLevels() 안에서 시작한 트랜잭션에 UserDao의 메소드들도 참여할 수 있다. upgradeLevels() 메소드 안에서 트랜잭션의 경계 설정 작업이 일어나야 하고, 그 트랜잭션을 갖고 있는 DB 커넥션을 이용하도록 해야만 별도의 클래스에 만들어둔 DAO 내의 코드도 트랜잭션이 적용될테니 결국 이 방법을 사용할 수 밖에 없다.
UserService 트랜잭션 경계설정의 문제점
이제 트랜잭션 문제는 해결했지만 여러가지 새로운 문제가 발생하게 된다.
- DB커넥션을 비롯한 리소스의 깔끔한 처리를 가능하게 했던
JdbcTemplate을 더이상 활용할 수 없다. 결국 JDBC API를 직접 사용하는 초기 방식으로 돌아가야 한다.try/catch/finally블록은 이제UserService내에 존재하고UserService의 코드는 JDBC 작업 코드의 전형적인 문제점을 그대로 가질 수 밖에 없다. - DAO의 메소드와 비즈니스 로직을 담고 있는
UserService의 메소드에Connection파라미터가 추가돼야 한다는 점이다.upgardeLevels()에서 사용하는 메소드의 어딘가에서 DAO를 필요로 한다면, 그 사이의 모든 메소드에 걸쳐서Connection오브젝트가 계속 전달돼야 한다.UserService는 스프링 빈으로 선언해서 싱글톤으로 되어 있으니UserService의 인스턴스 변수에 이Connection을 저장해뒀다가 다른 메소드에서 사용하게 할 수도 없다. 멀티 스레드 환경에서는 공유하는 인스턴스 변수에 스레드별로 생성하는 정보를 저장하다가는 서로 덮어쓰는 일이 발생하기 때문이다. 결국 트랜잭션이 필요한 작업에 참여하는UserService의 메소드는Connection파라미터로 지저분해질 것이다. Connection파라미터가UserDao인터페이스 메소드에 추가되면UserDao는 더이상 데이터 엑세스 기술에 독립적일 수 없다는 것이다. JPA나 하이버네이트로UserDao의 구현 방식을 변경하려고 하면Connection대신EntityManager나Session오브젝트를UserDao메소드가 전달받도록 해야 한다. 결국UserDao인터페이스는 바뀔 것이고 그에 따라UserService코드도 함께 수정돼야 한다. 기껏 인터페이스를 사용해 DAO를 분리하고 DI를 적용했던 수고가 물거품이 되고 말 것이다.- DAO 메소드에
Connection파라미터를 받게 하면 테스트코드에도 영향을 미친다. 지금까지 DB 커넥션은 전혀 신경쓰지 않고 테스트에서UserDao를 사용할 수 있었는데, 이제는 테스트 코드에서 직접Connection오브젝트를 일일이 만들어서 DAO 메소드를 호출하도록 모두 변경해야 한다.
트랜잭션 동기화
UserService 메소드 안에서 트랜잭션 코드를 구현하며 위와 같은 문제점을 감내할 수 밖에 없을까? 스프링은 사실 이 문제를 해결할 수 있는 멋진 방법을 제공한다.
Connection 파라미터 제거
현재까지 문제의 핵심은 UserService에서 Connection 객체를 만들어서 해당 객체를 2번이나 전달하느라 코드가 어지럽혀졌고 그 영향이 심지어 테스트코드까지 미쳤다는 것이다.
이런 문제를 해결하기 위해 스프링이 제안하는 방법은 독립적인 트랜잭션 동기화(transaction synchronization) 방식이다. 트랜잭션 동기화란 UserService에서 트랜잭션을 시작하기 위해 만든 Connection 오브젝트를 특별한 장소에 보관해두고, 이후에 호출되는 DAO의 메소드에서는 저장된 Connection을 가져다가 사용하게 하는 것이다. 정확히는 DAO가 사용하는 JdbcTemplate이 트랜잭션 동기화 방식을 이용하도록 하는 것이다. 그리고 트랜잭션이 모두 종료되면 그 때는 동기화를 마치면 된다.
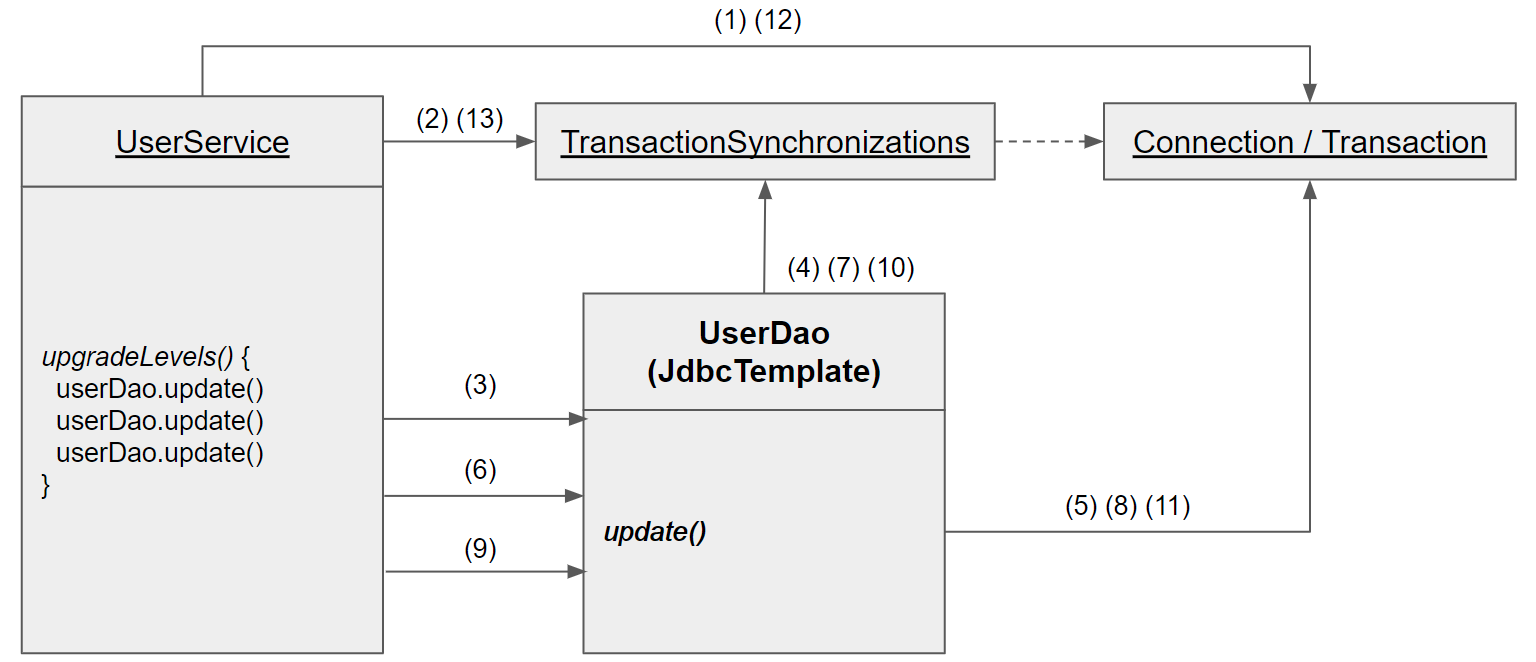
(1):UserService가Connection을 생성한다.(2): 생성한Connection을 트랜잭션 동기화 저장소에 저장한다. 이후에Connection의setAutoCommit(false)를 호출해 트랜잭션을 시작시킨다.(3): 첫 번째update()메소드를 호출한다.(4):update()메소드 내부에서 이용하는JdbcTemplate은 트랜잭션 동기화 저장소에 현재 시작된 트랜잭션을 가진Connection오브젝트가 존재하는지 확인한다. ((2)단계에서 만든Connection오브젝트를 발견할 것이다.)(5): 발견한Connection을 이용해PreparedStatement를 만들어 SQL을 실행한다. 트랜잭션 동기화 저장소에서 DB 커넥션을 가져왔을 때는JdbcTemplate은Connection을 닫지 않은채로 작업을 마친다. 이렇게 첫번째 DB 작업을 마쳤고, 트랜잭션은 아직 닫히지 않았다. 여전히Connection은 트랜잭션 동기화 저장소에 저장되어 있다.(6): 동일하게userDao.update()를 호출한다.(7): 트랜잭션 동기화 저장소를 확인하고Connection을 가져온다.(8): 발견된Connection으로 SQL을 실행한다.(9):userDao.update()를 호출한다.(10): 트랜잭션 동기화 저장소를 확인하고Connection을 가져온다.(11): 가져온Connection으로 SQL을 실행한다.(12):Connection의commit()을 호출해서 트랜잭션을 완료시킨다.(13):Connection을 제거한다.
위 과정 중 예외가 발생하면, commit()은 일어나지 않고 트랜잭션은 rollback()된다.
트랜잭션 동기화 저장소는 작업 스레드마다 독립적으로
Connection오브젝트를 저장하고 관리하기 때문에 다중 사용자를 처리하는 서버의 멀티스레드 환경에서도 충돌이 날 염려는 없다.
이렇게 트랜잭션 동기화 기법을 사용하면 파라미터를 통해 일일이 Connection 오브젝트를 전달할 필요가 없어진다. 트랜잭션의 경계설정이 필요한 upgradeLevels()에서만 Connection을 다루게 하고 여기서 생성된 Connection과 트랜잭션을 DAO의 JdbcTemplate이 사용할 수 있도록 별도의 저장소에 동기화하는 방법을 적용하기만 하면 된다.
더이상 로직을 담은 메소드에 Connection 타입의 파라미터가 전달될 필요도 없고, UserDao의 인터페이스에도 일일이 JDBC 인터페이스인 Connection을 사용한다고 노출할 필요도 없다.
문제의 핵심은 트랜잭션을 이용하기 위해
Connection이라는 파라미터를 귀찮게 2단계나 전달해야 했다는 것이다. 그리고 이 과정에서JdbcTemplate을 이용할 수 없게 되고 기존try/catch/finally방식의 단점이 그대로 다시 돌아왔었다.결국
Connection을 다른 저장소에 저장해두고 쓰는 방식이 필요했는데, 멀티쓰레드 환경이라는 제약 조건과UserService가 빈이라는 제약 조건이 있었다.스프링의 트랜잭션 동기화 저장소는 작업 스레드마다 독립적으로
Connection오브젝트 저장/관리 환경을 제공함으로써 이러한 문제를 해결했다.
트랜잭션 동기화 적용
트랜잭션 동기화의 아이디어 자체는 그냥 글로벌한 공간에 트랜잭션을 잠시 저장해둔다는 것으로 간단하지만, 멀티스레드 환경에서도 안전하게 트랜잭션 동기화를 구현하는 것이 기술적으로 간단하지는 않다. 다행히 스프링은 JdbcTemplate과 더불어 이런 트랜잭션 동기화 기능을 지원하는 간단한 유틸리티 메소드를 제공한다.
public class UserService {
UserDao userDao;
DataSource dataSource;
...위와 같이 현재 DataSource의 커넥션을 얻기 위해 DataSource 빈을 주입받아야 한다.
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="userDao" ref="userDao" />
<property name="dataSource" ref="dataSource" />
<property name="userLevelUpgradePolicy" ref="userLevelUpgradePolicy" />
</bean>xml에서 주입 설정을 해주자.
public void upgradeLevels() throws SQLException{
// 트랜잭션 동기화 관리자를 이용해 동기화 작업을 초기화
TransactionSynchronizationManager.initSynchronization();
// DB 커넥션을 생성하고 트랜잭션을 시작한다.
// 이후의 DAO 작업은 모두 여기서 시작한 트랜잭션 안에서 진행된다.
// 아래 두 줄이 DB 커넥션 생성과 동기화를 함께 해준다.
Connection c = DataSourceUtils.getConnection(dataSource);
c.setAutoCommit(false);
try {
List<User> users = userDao.getAll();
for (User user : users) {
if (canUpgradeLevel(user)) {
upgradeLevel(user);
}
}
c.commit();
}catch(Exception e) {
c.rollback();
throw e;
} finally {
// 스프링 DataSourceUtils 유틸리티 메소드를 통해 커넥션을 안전하게 닫는다.
DataSourceUtils.releaseConnection(c, dataSource);
// 동기화 작업 종료 및 정리
TransactionSynchronizationManager.unbindResource(this.dataSource);
TransactionSynchronizationManager.clearSynchronization();
}
}upgradeLevels에 위와 같은 트랜잭션 처리를 해주었다. 스프링을 사용하지 않고 JDBC를 이용해 Connection 객체를 직접 쓸 때와 다른 점은
- 첫째로 트랜잭션 동기화 관리(
TransactionSynchronizationManager)를 이용한다는 점 - 둘째로는 커넥션을 가져올 때나 반납할 때
DataSourceUtils라는 스프링 제공 유틸리티를 사용한다는 점
두가지가 있다.
더이상 DataSource.getConnection()을 이용해 Connection을 그냥 가져오지 않는 이유는 DataSourceUtils를 이용해 커넥션을 가져오고 setAutoCommit(false) 메소드를 수행하면, DB 커넥션 생성과 트랜잭션 동기화에 사용하도록 저장소에 바인딩해주기 때문이다.
트랜잭션 동기화가 되어 있는 채로 JdbcTemplate을 사용하면 JdbcTemplate의 작업에서 동기화시킨 DB 커넥션을 사용하게 된다. 결국 UserDao를 통해 진행되는 모든 JDBC 작업은 upgradeLevels() 메소드에서 만든 Connection 오브젝트를 사용하고 같은 트랜잭션에 참여하게 된다.
작업을 정상적으로 마치면 트랜잭션을 커밋해주고, 예외가 발생하면 롤백한다. 마지막으로는 커넥션을 안전하게 반환하고, 동기화 작업에 사용됐던 부분들을 바인드 해제한다.
JDBC의 트랜잭션 경계설정 메소드를 사용해 트랜잭션을 이용하는 전형적인 코드에 간단한 트랜잭션 동기화 작업만 붙여줌으로써, 지저분한 Connection 파라미터의 문제를 말끔히 해결했다.
JdbcTemplate과 트랜잭션 동기화
JdbcTemplate은 어떻게 트랜잭션을 이용하는지 다시한번 살펴보자. 일단, JdbcTemplate에서 update()나 query()와 같은 메소드를 사용했을 때 스스로 Connection을 만들었다가 반납한다는 것을 알 수 있다.
사실 JdbcTemplate에는 트랜잭션 동기화가 이미 고려된 설계가 적용되어 있다. 트랜잭션 동기화를 시작해놓았다면, 직접 DB Connection을 만드는 대신 트랜잭션 동기화 저장소에 들어있는 DB Connection을 가져와 사용한다. 이를 통해 이미 시작된 트랜잭션에 참여한다.
따라서 UserDao는 트랜잭션이 적용된다고 해서 따로 코드를 수정할 필요가 없다.
JdbcTemplate은 JDBC를 사용할 때 까다로울 수 있는
try/catch/finally작업 흐름 지원SQLException예외 변환- 트랜잭션 동기화 관리
와 같은 작업들에 대한 템플릿을 제공하여, 개발자가 비즈니스 로직에 집중할 수 있고 애플리케이션 레이어를 설계하기 좋은 환경을 만들어준다.
귀찮게 Connection 파라미터를 물고다니지 않아도 된다. 또한, UserDao는 여전히 데이터 액세스 기술에 종속되지 않는 깔끔한 인터페이스 메소드를 유지한다. 그리고 테스트에서 DAO를 직접 호출해서 사용하는 것도 아무런 문제가 되지 않는다.
5.2.4 트랜잭션 서비스 추상화
지금까지 UserService, UserDao, UserDaoJdbc를 만들면서 JDBC API를 사용하고 트랜잭션도 적용해보았다. 책임과 성격에 따라 데이터 액세스 부분과 비즈니스 로직을 잘 분리, 유지할 수 있게 만든 뛰어난 코드이다. JDBC를 사용하며 이보다 더 깔끔한 코드를 만들기는 힘들 것이다.
기술과 환경에 종속되는 트랜잭션 경계설정 코드
여기서 여러 DB에 걸쳐 트랜잭션 경계를 만들어야 하는 글로벌 트랜잭션이라는 새로운 요구사항이 들어왔다고 가정하자. 지금까지 사용한 JDBC의 Connection을 이용한 트랜잭션 방식은 로컬 트랜잭션이라 글로벌 트랜잭션을 이용하려면 무언가 다른 방법이 필요하다.
왜냐하면 로컬 트랜잭션은 하나의 DB Connection에 종속되기 때문이다. 따라서 각 DB와 독립적으로 만들어지는 Connection을 통해서가 아니라, 별도의 트랜잭션 관리자를 통해 트랜잭션을 관리하는 글로벌 트랜잭션(Global Transaction) 방식을 사용해야 한다.
글로벌 트랜잭션을 적용해야 트랜잭션 매니저를 통해 여러 개의 DB가 참여하는 작업을 하나의 트랜잭션으로 만들 수 있다. 또한 분산된 애플리케이션끼리 메세지를 받는 자바 메세지 서비스(JMS)와 같은 트랜잭션 기능을 지원하는 서비스도 트랜잭션에 참여시킬 수 있다.
자바는 JDBC 외에 이런 글로벌 트랜잭션을 지원하는 트랜잭션 매니저를 지원하기 위한 API인 JTA(Java Transaction API)를 제공하고 있다.
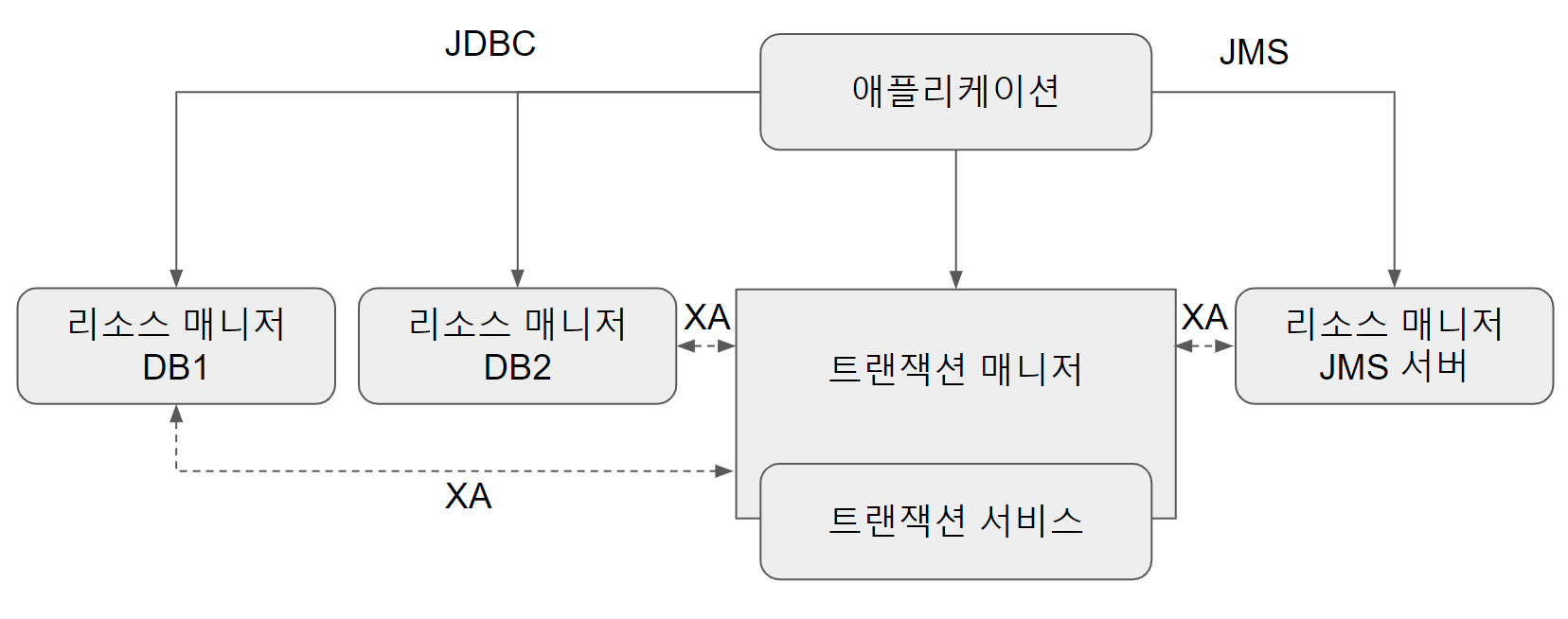
위 그림은 JTA를 이용해 여러 개의 DB 또는 메시징 서버에 대한 트랜잭션을 관리하는 방법을 보여준다.
- 애플리케이션은 기존의 방법대로 DB는 JDBC, 메시징 서버라면 JMS 같은 API를 사용해서 필요한 작업을 수행한다.
- 단, 트랜잭션은 JDBC나 JMS API를 사용하여 직접 제어하지 않고, JTA를 통해 트랜잭션 매니저가 관리하도록 위임한다.
- 트랜잭션 매니저는 DB와 메시징 서버를 제어하고 관리하는 각각의 리소스 매니저와 XA 프로토콜을 통해 연결된다.
이를 통해 트랜잭션 매니저가 실제 DB와 메시징 서버의 트랜잭션을 종합적으로 제어할 수 있게 된다. JTA를 이용하여 트랜잭션 매니저를 활용하면 여러 개의 DB나 메시징 서버에 대한 작업을 하나의 트랜잭션으로 통합하는 분산 트랜잭션 또는 글로벌 트랜잭션이 가능해진다. 하나 이상의 DB가 참여하는 트랜잭션을 만들려면 JTA를 사용해야 한다는 사실을 기억해두자.
// JNDI를 이용해 서버의 Transaction 오브젝트를 가져온다.
InitialContext ctx = new InitialContext();
UserTransaction tx = (UserTransaction)ctx.lookup(USER_TX_JNDI_NAME);
tx.begin();
// JNDI(Java Naming and Directory Interface)로 가져온 dataSource를 사용해야 한다.
Connection c = dataSource.getConnection();
try {
// 데이터 액세스 코드
tx.commit();
} catch (Exception e) {
tx.rollback();
throw e;
} finally {
c.close();
}JTA를 이용한 방법으로 바뀌긴 했지만 트랜잭션 경계 설정을 위한 구조는 JDBC를 사용했을 때와 비슷하다. Connection의 메소드 대신에 UserTransaction의 메소드를 사용한다는 점을 제외하면 트랜잭션 처리 방법은 별로 달라진 것이 없다. 코드의 구조도 비슷하다.
문제는 JDBC 로컬 트랜잭션을 JTA를 이용하는 글로벌 트랜잭션으로 바꾸려면 UserService의 코드를 수정해야 한다는 점이다.
로컬 트랜잭션이면 충분한 고객에게는 JDBC를 이용한 트랜잭션 관리 코드를 다중 DB를 위한 글로벌 트랜잭션을 필요로 하는 곳에는 JTA를 이용한 트랜잭션 관리 코드를 적용해야 한다는 문제가 생긴다.
UserService는 자신의 로직이 바뀌지 않았음에도 기술환경에 따라서 코드가 바뀌는 코드가 돼버리고 말았다.
이 상황에서 UserDao 인터페이스를 하이버네이트를 이용해 구현해야 하는 요구사항이 생기고, 그에 대한 트랜잭션 관리 코드를 구현해야 하는 요구사항이 생겼다고 가정해보자.
UserDao 인터페이스를 하이버네이트로 구현해도 트랜잭션 외의 UserService 메소드들은 잘 동작할 것이다. 그런데 또 트랜잭션이 걸린다. 하이버네이트를 이용한 트랜잭션 관리 코드는 JDBC나 JTA의 코드와는 또 다르기 때문이다.
하이버네이트는 Connection을 직접 사용하지 않고 Session이라는 것을 사용하고, 독자적인 트랜잭션 관리 API를 사용한다. 그렇다면 이번엔 UserService를 하이버네이트의 Session과 Transaction 오브젝트를 사용하는 트랜잭션 경계 코드로 변경할 수 밖에 없게 됐다.
트랜잭션 API의 의존관계 문제와 해결책
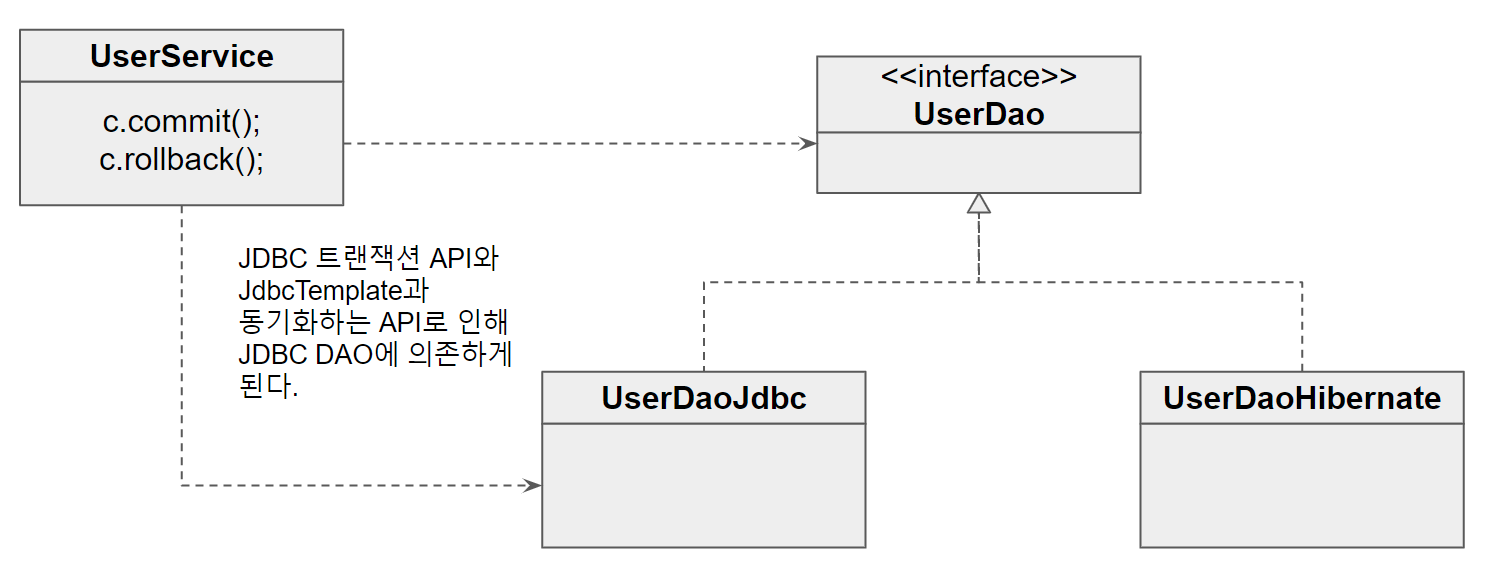
UserService는 원래 UserDao 인터페이스에만 의존하는 구조였다. 그래서 DAO 클래스의 구현 기술이 JDBC에서 하이버네이트나 여타 기술로 바뀌어도 UserService 코드는 영향을 받지 않았다. 전형적인 OCP 원칙을 지키는 코드였다.
문제는 JDBC에 종속적인 Connection을 이용한 트랜잭션 코드가 UserService에 등장하면서부터 UserService는 UserDaoJdbc에 간접적으로 의존하는 코드가 돼버렸다는 점이다. 기껏 UserDao 인터페이스를 사이에 두고 데이터 액세스 기술의 다양한 예외도 모두 추상화하고 DI를 적용해서 구현 클래스에 대한 의존도를 완벽하게 제거했는데 트랜잭션 때문에 그동안의 수고가 허사가 되고 말았다.
UserService의 코드가 특정 트랜잭션 방법에 의존적이지 않고 독립적으로 만들려면 어떻게 해야 할까? 다행히 트랜잭션의 경계설정을 담당하는 코드는 일정한 패턴을 갖는 유사한 구조다. 이렇게 여러 기술의 사용 방법에 공통점이 있다면 추상화를 생각해볼 수 있다. 추상화란 하위 시스템의 공통점을 뽑아내서 분리시키는 것을 말한다. 이렇게 하면 하위 시스템이 어떤 것인지 알지 못해도, 또는 하위 시스템이 바뀌더라도 일관된 방법으로 접근할 수 있다.
DB에서 제공하는 DB 클라이언트 라이브러리와 API는 서로 전혀 호환이 안되는 독자적인 방식으로 만들어졌지만, SQL을 이용하는 방식이라는 공통점을 뽑아내 추상화한 것이 JDBC이다. JDBC라는 추상화 기술이 있기 때문에 자바의 프로그램 개발자는 DB의 종류에 상관없이 일관된 방법으로 데이터 액세스 코드를 작성할 수 있다.
트랜잭션 코드에도 추상화를 도입해보자. JDBC, JTA, 하이버네이트, JPA, JDO 심지어 JMS도 트랜잭션 개념을 갖고 있으니 트랜잭션 경계설정 방법에서 공통점이 있을 것이며 공통적인 특징을 모아서 추상화된 트랜잭션 관리 계층을 만들 수 있을 것이다. 그러면 특정 기술에 종속되지 않는 트랜잭션 경계 코드를 만들 수 있을 것이다.
스프링의 트랜잭션 서비스 추상화
스프링은 트랜잭션 기술의 공통점을 담은 트랜잭션 추상화 기술을 제공한다. 이를 이용하면 특정 기술에 종속되지 않고 트랜잭션 경계 설정 작업이 가능해진다.
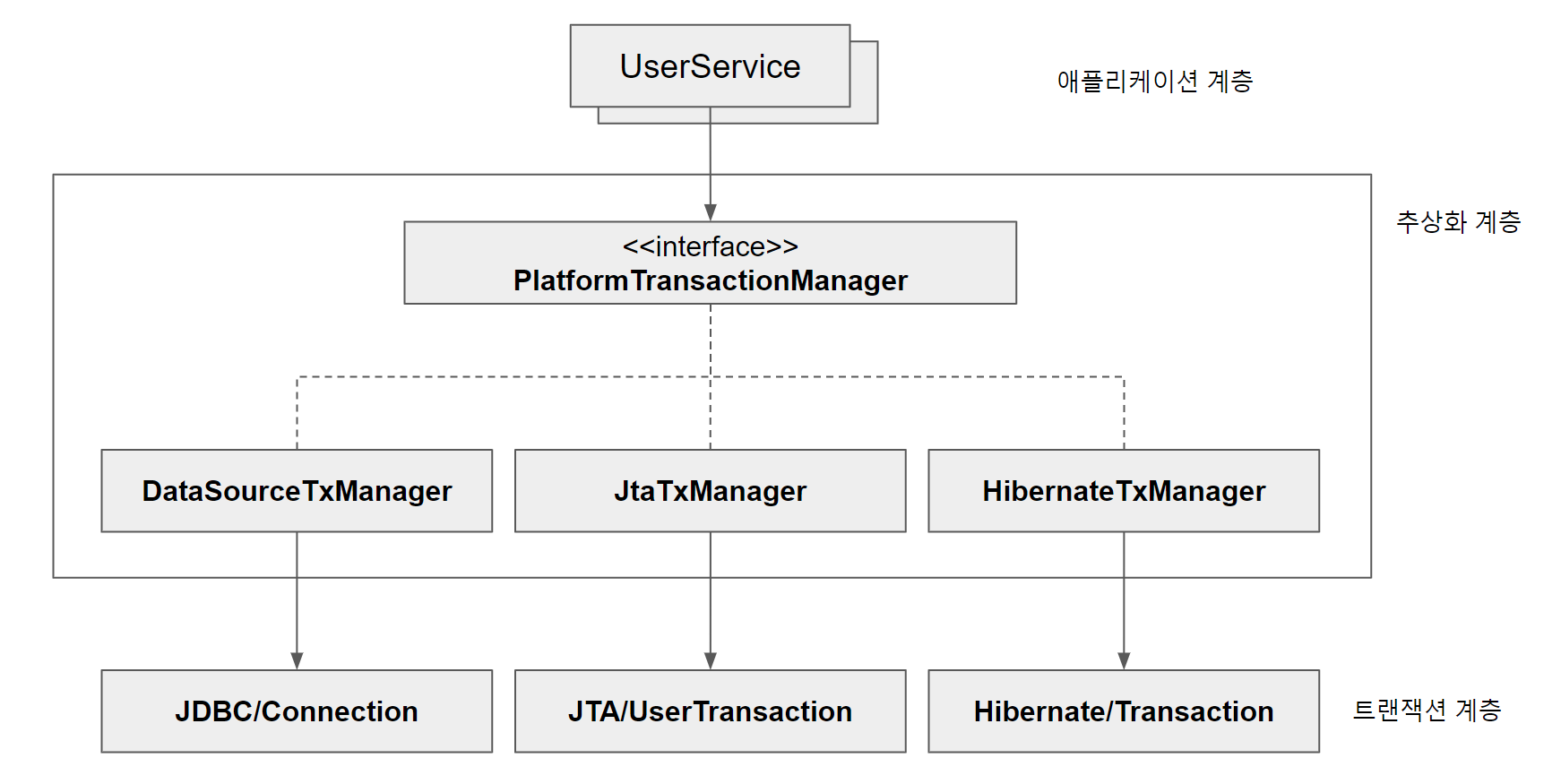
위는 스프링이 제공하는 트랜잭션 추상화 계층을 나타낸 그림이다.
PlatformTransactionManager를 적용해보자.
public class UserService {
UserDao userDao;
DataSource dataSource;
PlatformTransactionManager transactionManager;
...PlatformTransactionManager를 필드에 추가했다.
public void upgradeLevels() {
// 트랜잭션 시작
TransactionStatus status =
transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
List<User> users = userDao.getAll();
for (User user : users) {
if (canUpgradeLevel(user)) {
upgradeLevel(user);
}
}
transactionManager.commit(status);
}catch(Exception e) {
transactionManager.rollback(status);
throw e;
}
}upgradeLevels() 메소드는 더이상 JDBC라는 특정 기술에 의존하지 않는다.
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="transactionManager" ref="transactionManager"/>
<property name="userDao" ref="userDao" />
<property name="dataSource" ref="dataSource" />
<property name="userLevelUpgradePolicy" ref="userLevelUpgradePolicy" />
</bean>이를 위해 transactionManager를 만들어 주입해주었다. 이름은 transactionManager이지만 실제로는 PlatformTransactionManager 인터페이스에 주입될 빈이다.
테스트도 정상적으로 실행된다.
현재는 JDBC의 로컬 트랜잭션을 이용하기 위해 DataSourceTransactionManager를 생성하여 PlatformTransactionManager 인터페이스에 주입한 형태이다.
JDBC를 이용하는 경우에는 먼저 Connection을 생성하고 나서 트랜잭션을 시작했다. 하지만 PlatformTransactionManager에서는 트랜잭션을 가져오는 요청인 getTransaction() 메소드를 호출하기만 하면 된다. 필요에 따라 트랜잭션 매니저가 DB 커넥션을 가져오는 작업도 같이 수행해주기 때문이다. 트랜잭션을 가져오면서 트랜잭션이 시작된다. 파라미터로 넘기는 DefaultTransactionDefinition 오브젝트는 트랜잭션에 대한 속성을 담고 있다.
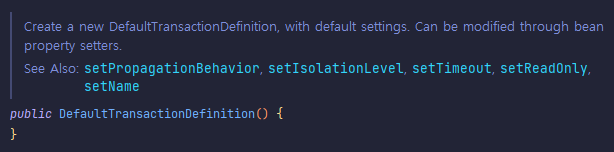
PropagationBehavior,IsolationLevel,Timeout,ReadOnly,Name등의 설정을 프로퍼티 setter를 통해 설정할 수 있다.
시작된 트랜잭션은 TransactionStatus 타입의 변수에 저장된다. Transactionstatus는 트랜잭션에 대한 조작이 필요할 때 PlatformTransactionManager 메소드의 파라미터로 전달해주면 된다.
스프링의 트랜잭션 추상화 기술은 앞서 살펴봤던 트랜잭션 동기화를 사용한다. 트랜잭션 동기화 저장소에 트랜잭션을 저장해두고 해당 트랜잭션을 이용해 데이터 액세스 작업을 수행 후 마지막에 commit과 rollback을 결정한다.
트랜잭션 기술 설정의 분리
이제는 JTA나 Hibernate 등으로 트랜잭션을 적용해도 UserService의 코드는 변경될 필요가 없다. 단순히 빈에 주입하는 DI만 다른 클래스로 바꿔주면 된다.

위 빈 설정 부분만 수정하면 데이터 액세스 기술이 변해도 그대로 트랜잭션을 이용할 수 있다. 하이버네이트라면 HibernateTransactionManager를 주입하고, JPA라면, JPATransactionManager를 주입하면 된다.
UserService의 트랜잭션 경계설정을 위한 getTransaction(), commit(), rollback() 메소드를 사용한 코드는 전혀 손댈 필요가 없다.
어떤 클래스든 스프링의 빈으로 등록할 때 먼저 검토해야 할 것은 싱글톤으로 만들어져 여러 스레드에서 동시에 사용해도 괜찮은가 하는 점이다. 참고로 스프링이 제공하는 모든 PlatformTransactionManager의 구현 클래스는 싱글톤으로 사용 가능하다.
스프링이 PlatformTransactionManager라는 긴 이름을 붙인 이유는 단순히 JTA의 TransactionManager와 혼동되지 않도록 지은 이름이기 때문에 보통 변수명은 관례상 transactionManager로 짓는다.
참고로 이제 UserService 클래스의 멤버 중 JDBC에 의존적인 DataSource는 더이상 필요 없다. 완전히 JDBC 의존성에서 벗어날 수 있다.
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="transactionManager" ref="transactionManager"/>
<property name="userDao" ref="userDao" />
<property name="userLevelUpgradePolicy" ref="userLevelUpgradePolicy" />
</bean>오직 DataSourceTransactionManager라는 특정 구현체를 위해서 dataSource를 주입해줄 뿐이다.
개선사항을 적용하며 바뀐 점
이제 아래의 설정만 고쳐도 DB 연결 기술, 데이터 액세스 기술, 트랜잭션 기술을 자유롭게 바꿔서 사용할 수 있게 되었다. 어떻게 이런 것들이 가능했는지 되돌아보자.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="dataSource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="username" value="postgres" />
<property name="password" value="iwaz123!@#" />
<property name="driverClass" value="org.postgresql.Driver" />
<property name="url" value="jdbc:postgresql://localhost/toby_spring" />
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userDao" class="toby_spring.user.dao.UserDaoJdbc">
<property name="jdbcTemplate" ref="jdbcTemplate" />
</bean>
<bean id="userLevelUpgradePolicy" class="toby_spring.user.service.user_upgrade_policy.OrdinaryUserLevelUpgradePolicy">
</bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="transactionManager" ref="transactionManager"/>
<property name="userDao" ref="userDao" />
<property name="userLevelUpgradePolicy" ref="userLevelUpgradePolicy" />
</bean>
</beans>수직, 수평 계층구조와 의존관계
UserDao와 UserService는 각각 담당하는 코드의 기능적인 관심에 따라 분리되었다. 사실 둘은 같은 애플리케이션 로직을 담은 코드이지만 내용에 따라 분리하여, 수평적으로 분리했다고 볼 수 있다.
트랜잭션의 추상화는 이와는 좀 다르다. 애플리케이션의 비즈니스 로직과 그 하위에서 동작하는 로우레벨의 트랜잭션 기술이라는 아예 다른 계층의 특성을 갖는 코드를 분리한 것이다.
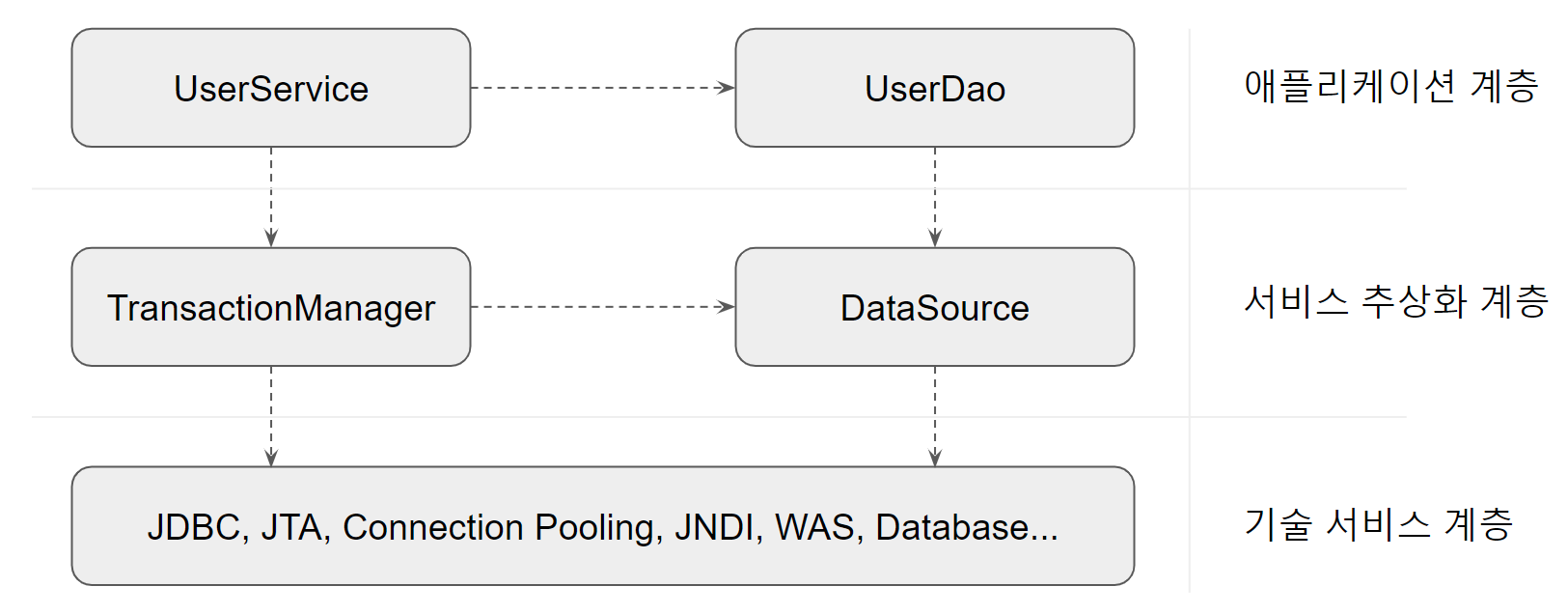
위 그림은 지금까지 만들어진 사용자 관리 모듈의 의존관계이다.
UserService,UserDao는 애플리케이션의 로직을 담으므로 애플리케이션 계층이다.UserDao는 데이터 등록, 조회 등 데이터 액세스에 대한 로직을 담는다.UserServce는 사용자 관리 업무의 비즈니스 로직을 담는다.UserDao와UserService는 인터페이스와 DI를 통해 연결됨으로써 결합도가 낮아졌다.
결합도가 낮다는 건 데이터 액세스 로직이 바뀌거나, 데이터 액세스 기술이 바뀐다고 할지라도 UserService의 코드에는 영향을 주지 않는다는 것을 의미한다. 서로 독립적으로 확장될 수 있는 부분이라는 뜻이다.
UserDao는 DB 연결을 생성하는 방법에 대해서도 독립적이다.DataSource인터페이스와 DI를 통해 추상화된 방식으로 로우레벨의 DB 연결 기술을 사용한다.
UserService는 트랜잭션 기술에 독립적이다.- 서버가 바뀌고 로우레벨의 트랜잭션 기술이 변경돼도
UserService는 영향을 받지 않는다.
- 서버가 바뀌고 로우레벨의 트랜잭션 기술이 변경돼도
UserDao와 DB연결 기술, UserService와 트랜잭션 기술의 결합도가 낮은 분리는 애플리케이션 코드를 로우레벨 기술 서비스와 환경에서 독립시켜준다.
애플리케이션 내부의 로직 종류에 따른 수평적 구분이든, 로직과 기술이라는 수직적인 구분이든 모두 결합도가 낮으며, 서로 영향을 주지 않고 자유롭게 확장될 수 있는 구조를 만들 수 있는 데는 스프링의 DI가 중요한 역할을 하고 있다.
DI의 가치는 관심, 책임, 성격이 다른 코드를 깔끔하게 분리하는 데에 있다.
단일 책임 원칙
적절한 분리가 가져오는 특징은 객체지향 설계의 원칙 중 하나인 단일 책임 원칙(Single Responsibility Principle)으로 설명할 수 있다.
단일 책임 원칙이란, 하나의 모듈은 한가지 책임을 가져야 한다는 의미다. 다른 말로 풀면 하나의 모듈이 바뀌는 이유는 한가지여야 한다고 설명할 수도 있다.
트랜잭션을 구현하기 위해 UserService에 JDBC 코드가 들어가있을 때는 UserService의 책임은 두가지였다.
- 어떻게 사용자 레벨을 관리할 것인가
- 어떻게 트랜잭션을 관리할 것인가
책임이 두가지라는 것은 코드가 수정되는 이유도 두가지라는 뜻이다.
- 레벨 관리 로직이 바뀌면?
UserService를 수정해야 한다. - 트랜잭션 기술이 바뀌면?
UserService를 수정해야 한다.
결국 위와 같이 2가지 이상의 책임을 가지는 순간 단일 책임 원칙은 깨지는 것이다.
하지만, 우리는 개선을 통해 트랜잭션 기술에 대한 부분은 PlatformTransactionManager라는 인터페이스를 두고 해당 기술에 맞는 xxxTransactionManager를 주입받도록 바꾸었다.
이제 '어떻게 트랜잭션을 관리할 것인가'는 더이상 UserService의 책임이 아니게 됐으며, '어떻게 사용자 레벨을 관리할 것인가'만 UserService의 책임이 되어 단일 책임 원칙을 잘 지키게 되었다.
이제는 사용자 관리 로직이 바뀌거나 추가되지 않는 한 UserService의 코드에 손댈 일이 없어졌다. 따라서 이제는 단일 책임 원칙을 훌륭하게 지키고 있다고 말할 수 있다.
단일 책임 원칙의 장점
좋은 설계 원칙이라기에 단일 책임 원칙을 지키긴 했는데 그렇다면 장점은 무엇일까?
단일 책임 원칙을 잘 지키고 있다면, 어떤 변경이 필요할 때 수정 대상이 명확해진다. 기술이 바뀌면 기술 계층과의 연동을 담당하는 기술 추상화 계층의 설정만 바꿔주면 된다. 데이터를 가져오는 테이블의 이름이 바뀌었다면 데이터 액세스 로직을 담고 있는 UserDao를 바꾸면 된다. 비즈니스 로직도 마찬가지다.
지금은 User라는 단순한 하나의 모듈만 있어서 장점을 체험하기 힘들 수도 있찌만 DAO가 각각 수백개가 되고 서비스 클래스도 그만큼 많다면 달라진다. 단일 책임 원칙을 지키지 않은 경우 클래스, 메소드 하나하나에 달린 의존 관계가 매우 복잡해진다. DAO를 수정할 때마다 그에 딸린 서비스 클래스를 같이 수정해야만 한다면? 수백개의 클래스를 같이 수정해야 할 뿐만 아니라, 테스트코드까지 수정해야 할지도 모르는 판이다.
기술적인 수정사항도 마찬가지다. 애플리케이션 계층의 코드가 특정 기술에 종속돼있다면? 이를테면 트랜잭션을 100군데에서 사용했는데, 데이터 액세스 기술이 JDBC에서 JPA로 바뀌었다면? 100군데 모두 일일이 찾아서 트랜잭션을 사용하는 부분을 수정해주어야 할 것이다.
단지 작업량만의 문제가 아니라, 많은 코드를 작업하면서 그만큼 실수가 일어날 확률도 증대한다. 운영중인 코드에 이런 수정이 필요하다면, 엄청난 부담이 될 것이다.
수정하기 쉬운 애플리케이션을 만들기 위해 필요한 것
적절하게 책임과 관심이 다른 코드를 분리하고, 서로 영향을 주지 않도록 다양한 추상화 기법을 도입하고, 애플리케이션 로직과 기술/환경을 분리하는 등의 작업은 갈수록 복잡해지는 엔터프라이즈 애플리케이션에는 반드시 필요하다. 이를 위한 핵심적인 도구가 바로 스프링이 제공하는 DI다.
DI가 없었다면? 나름 추상화를 했더라도 적지 않은 코드 사이 결합이 남게 된다. PlatformTransactionManager 인터페이스를 적용했지만, 코드 내부에 구체적인 타입이 new DataSourceTransactionManager()라는 것이 노출될 것이다. 이를테면 서비스가 100개면 100개의 서비스 모두에 new DataSourceTransactionManager()라는 구체적인 코드가 생기게 되고 변화가 생길 때마다 100개를 수정해야 한다. 물론 인터페이스로 추상화를 안했을 때보다는 훨씬 적지만, 로우레벨 기술의 변화가 있을 때마다 비즈니스 로직을 담은 코드의 수정이 발생한다.
객체지향 설계와 프로그래밍 원칙은 서로 긴밀하게 관련이 있다. 단일 책임 원칙을 잘 지키는 코드를 만들려면 인터페이스를 도입하고 이를 DI로 연결해주어야 한다. 그 결과로 단일 책임 원칙 뿐만 아니라 개방 폐쇄 원칙도 잘 지키고 모듈간에 결합도도 낮아져 서로의 변경이 영향을 주지 않고, 같은 이유로 변경이 단일 책임에 집중되는 응집도 높은 코드가 나온다.
이런 코드 개선 과정에서 전략 패턴, 어댑터 패턴, 브리지 패턴, 미디에이터 패턴 등 많은 디자인 패턴이 자연스럽게 적용되기도 한다. 객체지향 설계 원칙을 잘 지켜서 만든 코드는 테스트하기도 편하다. 스프링이 지원하는 DI와 싱글톤 레지스트리 덕분에 더욱 편리하게 자동화된 테스트를 만들 수 있다.
자연스레 좋은 설계가 나오기 까지는 몇달정도 공부하는 것으로는 되지 않는다. 개발하며 꾸준한 노력이 필요하다. 그저 기능이 동작한다고해서 코드에 쉽게 만족하지말고 계속 다듬고 개선하려는 자세도 필요하다.
지금까지 코드를 개선하고 발전시켜온 과정에는 DI가 항상 쓰였다.
UserDao와DataSource를 분리했을 때- 효과적인 단위 테스트를 만들 때
- 템플릿/콜백 패턴을 만들 때
- 비즈니스 로직을 데이터 로직과 별도로 만들어서 연결할 때
- 트랜잭션 기술을 추상화해서 분리할 때
스프링 의존관계 주입 기술인 DI는 모든 스프링 기술의 기반이 되는 핵심 엔진이자 원리이며 스프링이 지지하고 지원하는 좋은 설계와 코드를 만드는 모든 과정에서 사용되는 가장 중요한 도구이다.
객체지향 기술이나 패턴을 익히고 적용하는 일이 어렵고 지루하게 느껴지면, 스프링에서 DI가 어떻게 적용되고 있는지 살펴보며 이를 따라하는 것도 좋은 방법이다. 그러면서 좋은 코드의 특징이 무엇이고 가치가 있는지 살펴보는 것이다. 변경사유가 생겼을 때 코드의 어디를 어떻게 수정해야 하는지 주의 깊게 살펴보자.
DI의 원리를 잘 활용해서 스프링을 열심히 사용하면, 어느날 자신의 코드에 객체지향 원칙과 디자인 패턴의 장점이 잘 녹아있다는 사실을 발견할 수 있다.
이번 챕터의 목표
- 레벨이 업그레이드 되면 업그레이드 안내 메일을 보낸다.
- 사용자의 이메일 정보를 관리한다.
User에email필드를 추가한다.
UserService의upgradeLevel()에 메일 발송 기능을 추가한다.
- 사용자의 이메일 정보를 관리한다.
JavaMail을 이용해 메일 발송 기능 추가하기
사전 작업
- DB의
users테이블에email컬럼을 추가한다. User클래스에도email필드를 추가한다.insert(),update()와 같은 부분에email필드에 대한 부분을 추가해준다.- 기존 코드와 새로 추가된 필드가 잘 테스트되는지 확인 후에 작업을 진행한다.
JavaMail이 포함된 코드의 테스트
테스트 과정에서의 문제
- 메일서버(SMTP)가 준비되었을 때만 테스트가 가능하다.
- 테스트 시 매번 메일을 보내야 하는가?
- 메일 발송은 부하가 큰 작업이다.
- 테스트용 메일이 항상 실제로 발송되어 버린다.
- 많은 테스트를 한다면, 운영서버에 부담이 된다.
애플리케이션에서 자동화할 수 있는 프로세스는 결국 메일 서버에 내 요청이 잘 전송되었는지 까지가 바람직하다. 매번 직접 테스트에 사용된 메일에 들어가 메일을 확인할 수는 없는 노릇이다.
테스트 구조 생각해보기
- 실제 이메일을 보낼 때
UserService->JavaMail->실제 메일 서버
- 테스트 이메일을 보낼 때
UserService->JavaMail->테스트 메일 서버
받는 메일 서버만 달라진다. 이것만으로 네트워크 부하를 줄이고, 테스트를 간소화할 수 있다.
목표
- 실제 메일을 전송하는
JavaMail대신,JavaMail과 같은 인터페이스의 오브젝트를 만들어, 테스트에만 이용하자.
문제
- 메일을 보낼 때
Session오브젝트가 반드시 필요한데, 이 오브젝트는 인터페이스가 아닌final로 정의된 클래스이다.- 어떤 방식으로든
Session오브젝트를 상속받을 수 없다.
- 어떤 방식으로든
Transport클래스도Session과 동일하다.
JavaMailAPI의 인터페이스를 상속받아 테스트용 클래스를 구현하기는 현실적으로 힘들다.
문제 해결: 서비스 추상화 적용하기
JavaMail클래스 대신,JavaMail의 기능을 이용하는MailSender인터페이스 만들자.MailSender인터페이스에서JavaMail을 이용해 메일을 보내는 구현체를 만들면 된다.
MailSender 구현하기
사실 스프링 프레임워크에서 지원하기 때문에 따로 구현이 필요 없다.
// https://mvnrepository.com/artifact/org.springframework/spring-context-support
implementation group: 'org.springframework', name: 'spring-context-support', version: '5.3.15'위의 의존성을 추가하자.
Springframework의 MailSender 살펴보기
public interface MailSender {
/**
* Send the given simple mail message.
* @param simpleMessage the message to send
* @throws MailParseException in case of failure when parsing the message
* @throws MailAuthenticationException in case of authentication failure
* @throws MailSendException in case of failure when sending the message
*/
void send(SimpleMailMessage simpleMessage) throws MailException;
/**
* Send the given array of simple mail messages in batch.
* @param simpleMessages the messages to send
* @throws MailParseException in case of failure when parsing a message
* @throws MailAuthenticationException in case of authentication failure
* @throws MailSendException in case of failure when sending a message
*/
void send(SimpleMailMessage... simpleMessages) throws MailException;
}SimpleMailMessage타입을 받아 메일을 전송하는send()시그니처만 2개 정의되어 있다.
Springframework의 JavaMailSender 인터페이스 살펴보기
public interface JavaMailSender extends MailSender {
/**
* Create a new JavaMail MimeMessage for the underlying JavaMail Session
* of this sender. Needs to be called to create MimeMessage instances
* that can be prepared by the client and passed to send(MimeMessage).
* @return the new MimeMessage instance
* @see #send(MimeMessage)
* @see #send(MimeMessage[])
*/
MimeMessage createMimeMessage();
/**
* Create a new JavaMail MimeMessage for the underlying JavaMail Session
* of this sender, using the given input stream as the message source.
* @param contentStream the raw MIME input stream for the message
* @return the new MimeMessage instance
* @throws org.springframework.mail.MailParseException
* in case of message creation failure
*/
MimeMessage createMimeMessage(InputStream contentStream) throws MailException;
/**
* Send the given JavaMail MIME message.
* The message needs to have been created with {@link #createMimeMessage()}.
* @param mimeMessage message to send
* @throws org.springframework.mail.MailAuthenticationException
* in case of authentication failure
* @throws org.springframework.mail.MailSendException
* in case of failure when sending the message
* @see #createMimeMessage
*/
void send(MimeMessage mimeMessage) throws MailException;
/**
* Send the given array of JavaMail MIME messages in batch.
* The messages need to have been created with {@link #createMimeMessage()}.
* @param mimeMessages messages to send
* @throws org.springframework.mail.MailAuthenticationException
* in case of authentication failure
* @throws org.springframework.mail.MailSendException
* in case of failure when sending a message
* @see #createMimeMessage
*/
void send(MimeMessage... mimeMessages) throws MailException;
/**
* Send the JavaMail MIME message prepared by the given MimeMessagePreparator.
* <p>Alternative way to prepare MimeMessage instances, instead of
* {@link #createMimeMessage()} and {@link #send(MimeMessage)} calls.
* Takes care of proper exception conversion.
* @param mimeMessagePreparator the preparator to use
* @throws org.springframework.mail.MailPreparationException
* in case of failure when preparing the message
* @throws org.springframework.mail.MailParseException
* in case of failure when parsing the message
* @throws org.springframework.mail.MailAuthenticationException
* in case of authentication failure
* @throws org.springframework.mail.MailSendException
* in case of failure when sending the message
*/
void send(MimeMessagePreparator mimeMessagePreparator) throws MailException;
/**
* Send the JavaMail MIME messages prepared by the given MimeMessagePreparators.
* <p>Alternative way to prepare MimeMessage instances, instead of
* {@link #createMimeMessage()} and {@link #send(MimeMessage[])} calls.
* Takes care of proper exception conversion.
* @param mimeMessagePreparators the preparator to use
* @throws org.springframework.mail.MailPreparationException
* in case of failure when preparing a message
* @throws org.springframework.mail.MailParseException
* in case of failure when parsing a message
* @throws org.springframework.mail.MailAuthenticationException
* in case of authentication failure
* @throws org.springframework.mail.MailSendException
* in case of failure when sending a message
*/
void send(MimeMessagePreparator... mimeMessagePreparators) throws MailException;
}- 이전의
MailSender인터페이스를 구현하여 만든 인터페이스이다.SimpleMailMessage를 통해 메일을 보내는 시그니처를MimeMessage를 통해 보낼 수 있도록 구체화해두었다.
Springframework의 JavaMailSenderImpl 살펴보기
public class JavaMailSenderImpl implements JavaMailSender {
/** The default protocol: 'smtp'. */
public static final String DEFAULT_PROTOCOL = "smtp";
/** The default port: -1. */
public static final int DEFAULT_PORT = -1;
private static final String HEADER_MESSAGE_ID = "Message-ID";
private Properties javaMailProperties = new Properties();
@Nullable
private Session session;
@Nullable
private String protocol;
@Nullable
private String host;
private int port = DEFAULT_PORT;
@Nullable
private String username;
@Nullable
private String password;
@Nullable
private String defaultEncoding;
@Nullable
private FileTypeMap defaultFileTypeMap;
...
}사실 살펴보기엔 전체 코드가 너무 길다. 어찌됐든,
JavaMailSender를 동작하도록 잘 구현해놓았다.
Springframework의 JavaMailSenderImpl을 이용한 메서드 재구성
private void sendUpgradeEmailWithSpringMailSender(User user) {
JavaMailSenderImpl mailSender = new JavaMailSenderImpl();
mailSender.setHost("mail.ksug.org");
SimpleMailMessage mailMessage = new SimpleMailMessage();
mailMessage.setFrom("master@iwaz.co.kr");
mailMessage.setTo(user.getEmail());
mailMessage.setSubject("Upgrade 안내");
mailMessage.setText("사용자님의 등급이 " + user.getLevel().name() + "로 업그레이드 되었습니다.");
mailSender.send(mailMessage);
}MimeMessage를 추상화한SimpleMailMessage클래스를 이용해 코드가 훨씬 간결해졌다.- 내부적으로는 이전과 같이 JavaMail API를 이용해 메일을 전송할 것이다.
여전히 테스트용 오브젝트로 대체할 수는 없다.
DI 방식으로 코드 수정하기: applicationContext.xml
<bean id="mailSender" class="org.springframework.mail.javamail.JavaMailSenderImpl">
<!-- 메일서버 호스트 주소 -->
<property name="host" value="mail.ksug.org" />
</bean>
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="transactionManager" ref="transactionManager"/>
<property name="userDao" ref="userDao" />
<property name="userLevelUpgradePolicy" ref="userLevelUpgradePolicy" />
<property name="mailSender" ref="mailSender" />
</bean>mailSender빈을 추가하고,userService에 주입한다.
public class UserService {
// ...
public MailSender mailSender;
// ...
}- 직접 메서드에서 생성하지 않고, 의존성 주입을 받는다.
private void sendUpgradeEmailWithSpringMailSender(User user) {
SimpleMailMessage mailMessage = new SimpleMailMessage();
mailMessage.setFrom("master@iwaz.co.kr");
mailMessage.setTo(user.getEmail());
mailMessage.setSubject("Upgrade 안내");
mailMessage.setText("사용자님의 등급이 " + user.getLevel().name() + "로 업그레이드 되었습니다.");
mailSender.send(mailMessage);
}- 주입받은
MailSender를 이용하면 된다.
MailSender 인터페이스를 이용하는 것의 장점
- 다른 메일 서비스를 사용하더라도
MailSender인터페이스만 구현한 구현체만 만들면 언제든 DI를 통해 갈아끼울 수 있다. MailSender인터페이스 의존을 통해 기능을 확장해 놓으면, 다른 메일 서비스로도 똑같은 확장을 이용할 수 있다.- 이를테면, 메일 발송 큐를 만들어 정해진 시간에 메일을 보내게 할 수도 있다.
- 비즈니스 로직이 바뀌지 않는 한 메일 서비스가 아무리 바뀌더라도
UserService를 직접 수정할 일이 없다.- 객체지향원칙 중 하나인
OCP를 매우 잘 지키며, 관심사의 분리도 된다.
- 객체지향원칙 중 하나인
여전히 부족한 점: 트랜잭션
레벨 업그레이드 과정 중간에 어떠한 에러로 작업이 끊긴다면? 두가지 해결책이 있다.
- 첫째, 발송 대상과 내용만 별도의 목록에 저장해둔 뒤, 업그레이드가 마친 후에 메일을 보낸다.
- 둘째, 트랜잭션 개념이 있는 메일 전송용 클래스를 만든다.
- 이 방법도 첫째와 동일하게 전송 시에 목록에 저장해두고, 커밋 시점에 보낸다.
- 물론 예외가 발생하면 취소된다.
두 방법의 장단점 살펴보기
일단 둘 다 비슷한 방법이고, 문제를 해결할 수 있긴 하다. 그러나 둘째 방법이 설계상 조금 낫다.
- 첫째 방법은 사용자 관리 비즈니스 로직과 메일 발송 로직이 섞이게 된다.
- 둘째 방법은 사용자 관리 비즈니스 로직과 메일 발송 로직이 명확히 나뉜다.
로직이 명확히 나뉘면 테스트, 변화에 이점을 갖게 된다.
설정 파일 혹은 클래스를 따로 만드는 이유
이전에 test-applicationContext.xml과 applicationContext.xml 파일을 따로 구성햇는데, 그 이유는 테스트와 일반 애플리케이션의 영역을 나누기 위해서였다.
DummyMailSender
public class DummyMailSender implements MailSender {
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
}테스트 영역에 위와 같이 DummyMailSender를 만든다면 무슨 의미가 있을까? 생각보다 많은 의미가 있다.
test-applicationContext.xml과 같이 테스트에 사용될 수 있다.
사실 위와 같은 방법은 테스트 환경에서 이미 많이 사용되는 방법이다.
의존 오브젝트를 변경하는 테스트 방법
- 테스트용 설정파일을 이용해 테스트용 DB(in-memory DB 혹은 개발 DB)를 사용하는 방식을 떠올리면 된다.
DummyMailSender로MailSender를 대체하여 마치 메일이 보내지는 것처럼 부담없이 테스트할 수 있다.
변화하는 애플리케이션을 만드는 것은 뒤로 하고 테스트만을 위해서라도 DI는 매우 유용하다.
테스트 대역의 종류와 특징
DummyMailSender와 같이 테스트 환경을 만들어주기 위한 오브젝트를 테스트 대역(test double)이라고 한다.
테스트 스텁
그 중에서 DummyMailSender는 테스트 스텁에 속한다. 테스트 스텁은 의존 객체로 테스트 동안 코드가 정상 동작하도록 돕는 오브젝트이다. 값을 반환하거나, 예외를 던지거나, 아무것도 안하거나 다양하게 사용된다. 중요한 건 그러한 상황에서 앱이 어떻게 반응하냐를 테스트하는 것이다.
목 오브젝트
단순히 실행 결과만을 테스트하는 것이 아닌, 실행 과정에서 일어나는 커뮤니케이션을 테스트할 수 있도록 도와주는 오브젝트이다.
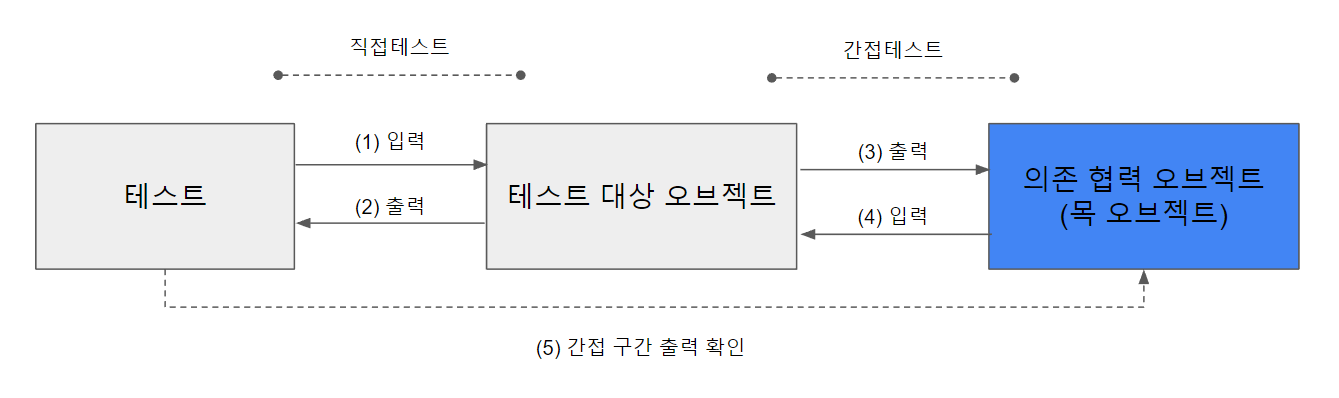
(5)를 빼면 테스트 스텁이다.- 테스트 오브젝트는 테스트 중에도 여러 다른 오브젝트와 커뮤니케이션하므로 그 과정에서 일어나는 입출력도 검증이 필요한 경우가 있다.
목 오브젝트를 이용해 테스트 구성해보기
이 과정에서
MailSender를 빈에 넣고 테스트해야 되는데, 책에 나온것처럼 스프링 3버전을 기준으로javax.mail패키지를 깔면 에러가 난다. 스프링 5에서는jakarta.mail을 이용해야 에러가 나지 않으니 주의하자.
https://docs.spring.io/spring-framework/docs/5.3.3/reference/html/integration.html#mail
항상 공식문서를 참고하자.
MockMailSender 구성하기
public class MockMailSender implements MailSender {
private final List<String> requests = new ArrayList<>();
public List<String> getRequests() {
return requests;
}
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
String[] to = simpleMessage.getTo();
requests.addAll(Arrays.asList(Objects.requireNonNull(to)));
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
}테스트 코드 작성
<bean id="mailSender" class="toby_spring.user.mail_sender.MockMailSender">
</bean>
<bean id="userService" class="toby_spring.user.service.UserService">
<property name="transactionManager" ref="transactionManager"/>
<property name="userDao" ref="userDao" />
<property name="userLevelUpgradePolicy" ref="userLevelUpgradePolicy" />
<property name="mailSender" ref="mailSender" />
</bean>- 테스트용 설정파일에는
MockMailSender를 주입해준다.
class UserServiceTest {
// ...
// 테스트에서는 `MockMailSender`를 주입받음
@Autowired MockMailSender mockMailSender;
// ...
}- 주입 받는 것도
MockMailSender를 주입받는다.
@Test
@DisplayName("사용자 레벨 업그레이드 후 이메일 보내는지 - 목오브젝트 이용")
public void upgradeLevelsWithEmail() throws SQLException {
for (User user : users) {
userDao.add(user);
}
userService.upgradeLevels();
checkLevelUpgraded(users.get(0), false);
checkLevelUpgraded(users.get(1), true);
checkLevelUpgraded(users.get(2), false);
checkLevelUpgraded(users.get(3), true);
checkLevelUpgraded(users.get(4), false);
List<String> request = mockMailSender.getRequests();
// 업그레이드 대상은 둘이므로 둘을 이메일 수신대상으로 잘 설정하고 있는지 테스트
Assertions.assertEquals(request.size(), 2);
Assertions.assertEquals(request.get(0), users.get(1).getEmail());
Assertions.assertEquals(request.get(1), users.get(3).getEmail());
}- 테스트 코드를 작성하면 두명에게 업그레이드 대상 두명에게 이메일을 잘 보내는지 알 수 있다.
- 테스트는 잘 성공한다.
- 메일 발송에 대한 추가적인 테스트가 필요할 때는 순수하게 이메일 발송만 테스트해보아도 좋다.
@DirtiesContext를 이용한 테스트
@DirtiesContext
class UserServiceTest {
// ...
}
@Test
@DisplayName("사용자 레벨 업그레이드 후 이메일 보내는지 - 목오브젝트 이용")
public void upgradeLevelsWithEmail() throws SQLException {
MockMailSender mockMailSender = new MockMailSender();
userService.setMailSender(mockMailSender);
for (User user : users) {
userDao.add(user);
}
userService.upgradeLevels();
checkLevelUpgraded(users.get(0), false);
checkLevelUpgraded(users.get(1), true);
checkLevelUpgraded(users.get(2), false);
checkLevelUpgraded(users.get(3), true);
checkLevelUpgraded(users.get(4), false);
List<String> request = mockMailSender.getRequests();
// 업그레이드 대상은 둘이므로 둘을 이메일 수신대상으로 잘 설정하고 있는지 테스트
Assertions.assertEquals(request.size(), 2);
Assertions.assertEquals(request.get(0), users.get(1).getEmail());
Assertions.assertEquals(request.get(1), users.get(3).getEmail());
}- 설정파일로 주입하지 않고 애플리케이션 컨텍스트를 더럽히며 테스트하는 방법이다.
- 컨텍스트를 더럽히지만 메서드 내 의도는 더 명확히 드러나는 편이다.
정리
- 비즈니스 로직을 담은 코드와 외부 모듈(JDBC, 메일서비스 등)을 이용하는 코드는 분리하자.
- 비즈니스 로직 코드 자체도 책임과 역할에 따라 메서드로 잘 정리하자.
- 인터페이스와 DI가 이를 도와준다.
- 데이터를 엑세스하는 로직에는 단위작업을 보장하는 트랜잭션이 필요하다.
- 트랜잭션의 시작과 종료를 지정하는 일을 트랜잭션 경계설정이라고 하며, 비즈니스 로직 안에서 일어나는 경우가 많다.
- 스프링이 제공하는 트랜잭션 동기화 기법을 이용해 간단히 경계설정이 가능하다.
- 다만, DB접근 API에 따라 방법이 조금 달라질 수 있다.
- 트랜잭션 방법이 달라져도 비즈니스 로직을 담은 코드는 변경되지 않아야 한다.
- 이 때 스프링의 트랜잭션 서비스 추상화가 도움을 준다.
JavaMail과 같은 확장하기 힘든 API를 다룰 때도 서비스 추상화를 이용하여, 좀 더 테스트하기 쉬우며 객체지향 원칙을 따르는 코드로 변경할 수 있다.- 서비스 추상화를 통해 테스트에서 의존 오브젝트를 대체하는 테스트 대역을 만들 수 있다.
- 커뮤니케이션하는 정보를 검증이 없다면, 단순히 테스트 스텁이라고 하고 커뮤니케이션하는 정보를 검증한다면 목오브젝트라 한다.
'프레임워크 > 토비의 스프링' 카테고리의 다른 글
| 토비의 스프링 4장 요약 정리 - 예외 처리 (0) | 2022.06.21 |
|---|---|
| 토비의 스프링 3장 요약 정리 - 템플릿 (0) | 2022.06.20 |
| 토비의 스프링 2장 요약 정리 - 테스트 (2) | 2021.12.26 |
| 토비의 스프링 1장 요약 정리 - 오브젝트와 의존관계 (3) | 2021.12.26 |
| 토비의 스프링 0장 정리 (0) | 2021.12.14 |